백준 이중 우선순위 큐 문제는, 큐에 있는 최소값과 최대값을 빠르게 찾아야 하는 문제입니다. 우선 순위가 제일 높은 것과 낮은 것을 찾아야 합니다. 그런데, 연산 횟수가 꽤 많기 때문에 이를 효율적으로 찾아야 합니다.
그런데, 우리가 알고 있는 우선순위 큐는 어떤가요? priority가 가장 높은 것을 찾는 것이라고 했어요. 고로, pq는 2개가 필요함을 알 수 있어요. 이 글에서는 어떻게 pq 2개로 푸는지 간략하게 설명해 드리겠습니다.
자료 구조 설계하기
pq는 2개가 필요합니다.
- 가장 큰 수가 우선 순위가 높은 pq
- 가장 작은 수가 우선 순위가 높은 pq
그런데, 문제가 하나 있습니다. 먼저, 우선순위 큐에서, 우선순위가 제일 낮은 원소를 찾는 것은 효율적이지 않습니다. 왜? priority가 높은 것은 root이지만, 낮은 것은 leaf 중 하나이기 때문입니다. 예를 들어, 큰 수가 우선순위가 높다고 생각해 봅시다. 그러면, 아래도 pq를 만족시킵니다.
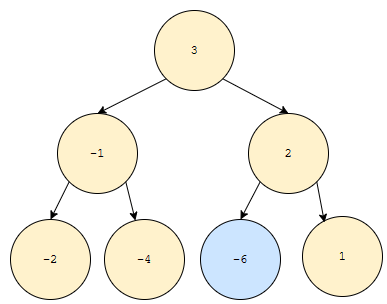
가장 우선 순위가 낮은 것은 파란색으로 표시해 두었습니다. 아래는 어떤가요?
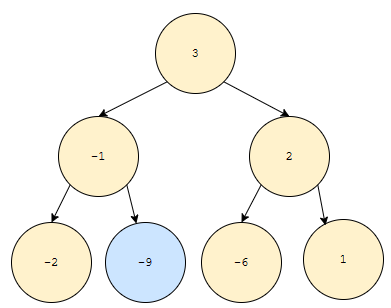
이것도 만족시켜요. 어떻게 찾아야 할까요? 찾았다고 해 봅시다. 예를 들어 -9를 찾았다고 해 봅시다. 그래서 제거했어요. 이제 다음으로 우선 순위가 낮은 건 어떻게 찾아야 할까요?
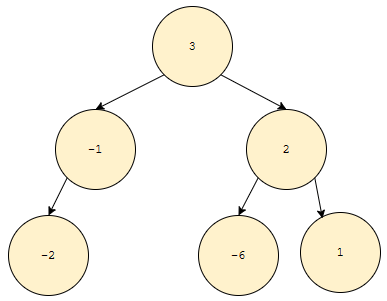
찾기가 쉽지 않습니다. 그러므로, 우선 순위가 가장 낮은 것을 찾는 것은 포기하면 편합니다. 대신에, pq 2개를 넣습니다.
- 최소값이 제일 priority가 높은 pq
- 최대값이 제일 priority가 높은 pq
그러면, 큐에 있는 최대값과 최소값을 빠르게 찾아낼 수 있습니다. 단, 삭제가 없다는 전제 하에서요.
marking
삭제가 있다면 어떻게 할까요? mark and sweep 은 많이 들어보셨을 겁니다. 삭제된 것은 표시해 두고 나중에 처리한다. 예를 들어, 아래와 같은 데이터가 있다고 해 볼게요.
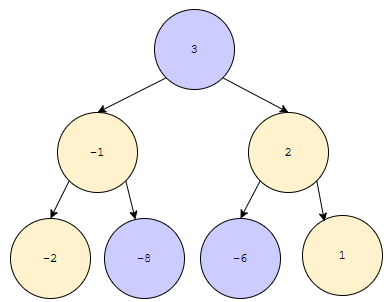
여기서 보라색은 삭제된 것들입니다. 큰 값이 우선순위가 높은 상황입니다. 이 pq에서 최대값을 찾아 봅시다. 먼저, 맨 위에 있는 3을 뽑습니다.

그런데 보라색으로 표시되어 있어요. 이미 제거되었다는 의미입니다. 자료구조에는 남아 있는 쓰레기입니다. 의미가 없지요? 따라서, 제거합니다.
다시 힙을 구축한 뒤에, 제일 위에 있는 것을 뽑아 봅시다.
이번엔 어때요? 제거되지 않았습니다. 따라서, 최대값은 2가 됩니다. 여기까지 우선순위가 높은 것을 어떻게 찾았는지 정리해 봅시다.
- 각 노드에는 제거되었는지 그렇지 않았는지 표시가 되어 있습니다.
- 맨 위에서 우선순위가 제일 높은 원소를 뽑습니다. 이 때
- 제거되었다면 자료구조에서 제거만 하고 2를 반복합니다.
- 그렇지 않으면 해당 원소가 우선순위가 제일 높습니다.
즉, 의미 없는 노드도 일단 marking을 해 두었다가, 실제 우선 순위가 높은 데이터를 pick 할 때 쓴다는 것이 포인트입니다. 어떻게 보면 지연 평가와 유사한 방식으로 동작한다고 봐도 무난할 듯 싶네요.
marking 여부 관리하기
그런데, 한 가지 남은 것이 있습니다. 각 노드별로 제거되었는지 여부를 어떻게 관리할까요? 우선 순위가 다른 pq에 들어가면 같은 노드라도 다른 위치에 들어가 있을 겁니다. 이 말은 두 자료구조가 공통으로 볼 수 있는 위치에 제거 여부를 관리해야 한다는 말이 됩니다.
각 노드별로 unique 한 것은 추가 시각입니다. 따라서, 추가된 시각을 기반으로 관리해 주면 됩니다. 예를 들어, 2, -1 순으로 추가되었다고 해 봅시다.
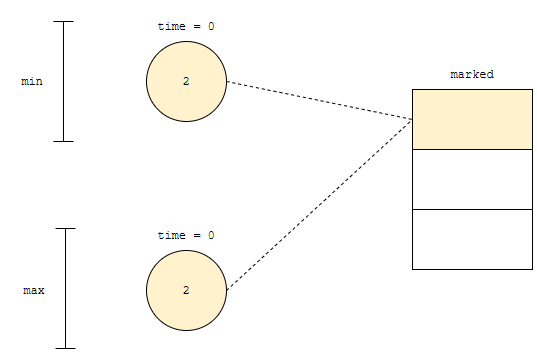
2가 추가된 후에 상태는 위와 같습니다. 다음에 -1을 추가해 봅시다.
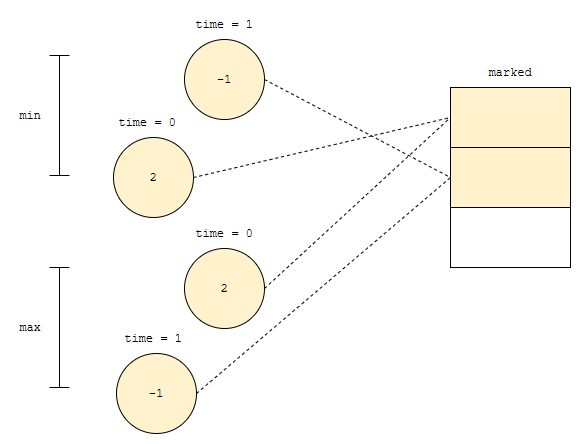
그러면, 요런 그림이 만들어 집니다. 각 노드에 추가된 시각 정보까지 같이 넣으면 어떨까요? 서로 다른 두 heap 에서 가장 우선 순위가 높은 것을 빼 버렸을 때, 실제 있는 것인지를 판단할 수 있겠지요. 예를 들어, 이 상태에서, 최대값을 제거해 봅시다.
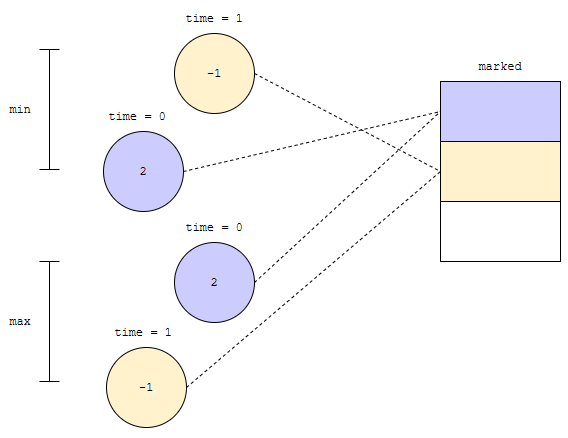
최대값은 2입니다. max heap의 top에는 시각 0에 추가된 노드가 있었어요. 그렇기 때문에, 제거하면서 시각 0에 추가된 노드는 제거되었다는 정보를 넣는 것입니다. 이 정보는 max heap뿐만 아니라 min heap에서도 볼 수 있어요. 왜? 제거되었는지 여부를 참조할 수 있는, 추가된 시각은 안 변하기 때문입니다.
즉 marked의 정의는 아래와 같습니다.
marked[time]
time에 추가된 노드가 제거되었으면 1, 아니면 0
“추가된 이벤트”를 가지고 무언가를 하고 있네요? event 기반으로 처리하고 있음을 알 수 있어요. 의미 없는 데이터를 marking 해 놓았다가 버리는 아이디어는 제가 많이 출제했습니다. 이 문제들로 연습해 보시면 좋겠습니다.
이제 이를 토대로 이중 우선순위 큐 문제의 코드를 보겠습니다.
코드 간략하게 보기
이중 우선순위 큐 문제를 해결한 코드 중 일부입니다. 코드가 길기 때문에 중요한 로직 위주로만 보도록 할게요.

먼저, 자료구조와 자료형을 봅시다. item에는 x와 time이 있어요. x는 pq에 넣은 값, time은 추가된 시각을 의미합니다. 즉, time은 이벤트가 발생한 시각을 의미해요. 이 값은 수가 같아도 unique하게 들어갑니다.
mini와 maxi는 compare 구조체이고요. exist 배열은 time에 추가된 값이 실제로 있는지를 저장합니다.
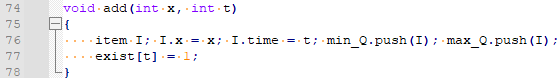
추가 연산부터 봅시다. x는 값, t는 추가 시각입니다. min_Q와 max_Q에 추가한 다음에 t에 추가된 수가 있다는 것을 저장합니다.

max_Q에서 제거하는 걸 봅시다. max_Q가 비어 있지 않을 때 까지 돌리는 건 같습니다. 중요한 것은, 큐에서 빠진 item에는 추가된 시각도 있었어요. 이 때 추가된 노드가 실제로 제거되었다면, while loop를 빠져나가지 않아요.
왜? 이미 제거된 것이기 때문이에요. exist[time]이 1이라는 것은, 제거가 안 되었다는 것입니다. 따라서, marking 처리만 하고 빠져나옵니다. 전체 코드는 링크에 있으니 참고하시면 좋겠습니다.