이 글에서는 linked hashmap 클래스를 HashMap만 이용해서 구현해 봅니다. 그리고, 이를 이용해서 lru 구현을 해 보도록 합시다. 이 글을 통해 우리는 java linkedhashmap 동작 방식에 대해 이해할 수 있습니다.
lru를 구현하는 방식은 3가지가 있는데요. 여기에서는 2번째 방법에 대해 다룹니다.
- monotone queue + hashmap
- linkedlist + hashmap [현재글]
- hashmap 2개
hashmap과 무엇이 다른가?
기본적으로 hashmap은 key, value 쌍을 저장합니다. 이 value에, 이전 노드와 현재 노드의 정보를 저장하면, linkedhashmap이 됩니다. 실제로, 해당 클래스는 추가적으로 링크 정보를 value에 저장하게 됩니다.
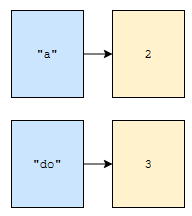
위 그림을 봅시다. key가 “a”인 것의 value는 2입니다. 그리고 “do”인 것의 value는 3입니다. 그런데, 링크에 대한 정보까지 들어가면 어떻게 될까요?
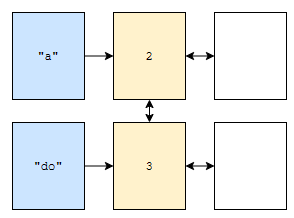
head, 3, 2, tail 순으로 연결되어 있다고 해 보겠습니다. 그러면, key가 “do”인 것의 value에는 아래와 같은 정보가 저장되어 있습니다.
- 3
- 이전 노드는 head이다.
- 다음 노드는 2가 저장되어 있는 노드.
이 경우, 기존 hashmap에 순서도 같이 저장할 수 있습니다. linkedlist와 비교하면 어떤 장점이 있을까요? 기존의 리스트를 생각해 봅시다.
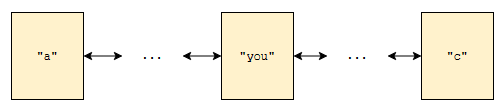
더블 링크드 리스트입니다. 여기서 “you”를 지우고 싶어요. 어떻게 해야 할까요? 우리는 맨 처음 원소인 “a”와, 맨 마지막 원소인 “c”의 위치는 알고 있습니다. 그런데, “you”의 위치는 들고 있지 않아요. 그렇기 때문에, “you”를 만날 때 까지 계속 head 에서부터 next를 타거나, tail 에서부터 prev를 타야 합니다.
리스트에 원소가 n개 있으면, 요래 구현된 경우 탐색하는 데 O(n)이 걸릴 겁니다.
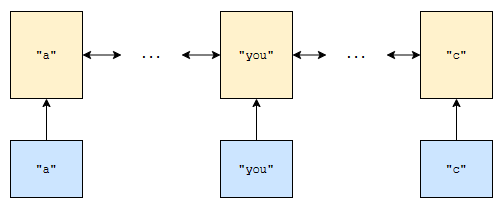
대신에, 이 linked list의 하나 하나의 원소들을 value로, 원소들의 값을 key로 삼아서 hashmap을 만들면 어떤가요? 키 “you”에 걸리는 원소를 찾기 위해 O(n)이 아니라 상수나 로그 시간만에 찾을 수 있습니다. 엄청나게 빠른 셈입니다.
결국, 우리는 삭제할 요소의 위치를 빠르게 알 수 있어서 유용합니다. 여기까지 java linkedhashmap 의 대략적인 구조입니다. 우리는 이를 바탕으로 lru cache 를 구현해 볼 거에요.
초기화 하기
먼저, 클래스의 필드들을 정의해 봅시다.
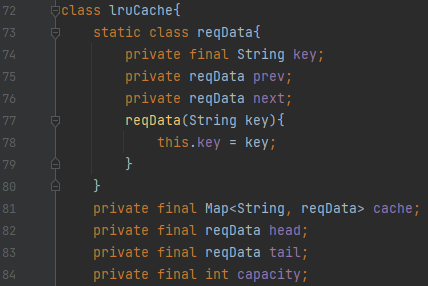
reqData 부분을 봅시다. key와 prev, next가 있는데요. key는 실제 키 값을 의미합니다. 그리고, prev와 next는 이전 노드와 다음 노드를 가리키게 될 겁니다. 이 cache에는 리스트의 노드가 value로 들어가기 때문에, head와 tail을 알아야 합니다. capacity는 캐시의 크기를 의미해요.

생성자를 봅시다. cache와 capacity는 별로 어렵지 않습니다. head의 다음 원소는 tail, tail의 이전 원소는 head로 초기화를 함을 알 수 있어요. 이는 더미 노드들을 생성하기 위해서에요. 그렇게 하면, head와 tail을 제거하는 case를 없앨 수 있어요.
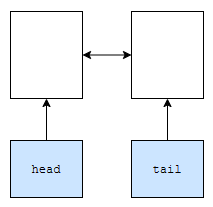
실제 linkedlist는 아래와 같이 초기화가 됩니다.
lru access 구현하기 1
이제, access 연산을 구현해 봅시다. 여기에서 필요한 연산은 2개입니다.
- cache에 있는 원소 수 구하기
- 가장 오래 전에 접근한 원소 구하기
- 원소 추가하기
- 원소 제거하기
1번째 질문. cache는 HashMap으로 관리됩니다. 그렇기 때문에, HashMap의 크기를 구하면 됩니다. 2번째 질문은 오래 전에 접근한 원소를 어떻게 구하냐인데요.
- head에 가까운 쪽은 오래 전에 접근이 된 것
- tail쪽에 가까운 것은 최근에 접근이 된 것
이라는 규칙을 두면 어떨까요? head에서 next를 타고 들어가면, 그 원소가 제일 오래 전에 추가된 것이 됩니다. 물론, HashMap의 크기가 0이면 그런 게 없겠네요. 3번째와 4번째가 문제네요. 원소 추가는 맨 마지막에만 추가됩니다. 이는 원소가 추가되면 최근에 접근이 되어 버리기 때문입니다. 즉, add_last를 구현하면 됩니다.
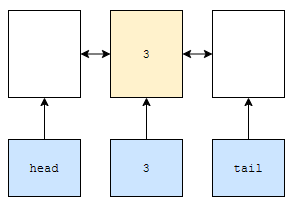
어디와 어디 사이에 추가하면 될까요? tail와 tail.prev 사이에 추가하면 됩니다.
- prev_item은 tail.prev가 됩니다.
- next_item은 tail이 됩니다.
새로 추가된 node에는 5라는 데이터가 들어가 있습니다. 이를 cur_item이라고 하면 아래와 같이 추가하면 됩니다.
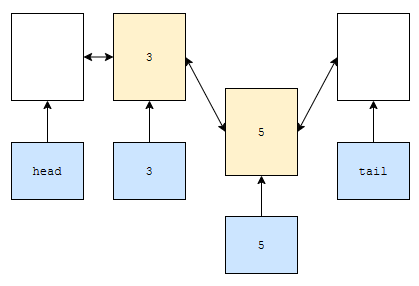
- prev_item.next는 cur_item, cur_item.next는 tail
- tail.prev는 cur_item, cur_item.prev는 prev_item
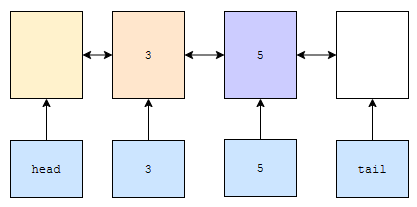
그러면 그림이 아래와 같이 그려질 겁니다.

다음에, 새로 추가된 노드와 5를 연관 시켜야 합니다. 즉, key값이 5이고, value를 5라는 정보를 가진 새로 추가된 노드인 정보를 hashMap에 추가합니다.
이를 코드로 구현하면 아래와 같습니다.
리스트의 맨 마지막에 key를 넣습니다. 그리고, 맨 마지막에 cache에 key에 대응되는 값은 cur_item 이라는 정보를 넣습니다. 여기서 cur_item은 key라는 정보를 가지고 있어요.
lru access 구현하기 2
그러면 remove는 어떻게 구현할까요? 이것도 어렵지 않습니다.
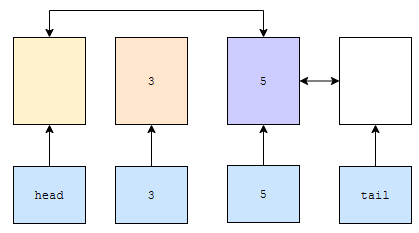
3을 삭제한다고 해 볼게요. 삭제할 원소의 prev는 노란색 원소입니다. 삭제할 원소의 다음 원소는 보라색 원소인 5입니다. 노란색의 다음 원소가 보라색이고, 보라색의 이전 원소가 노란색이라는 정보로 업데이트 합니다.
그러면 위와 같이 될 겁니다. 이 상황에서 3은 삭제된 것이지요? 따라서, cache에서도 제거합니다.
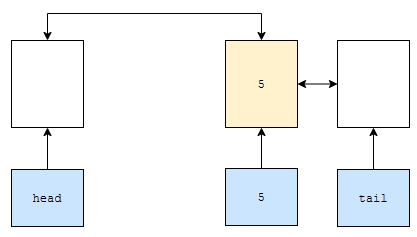
그러면 cache에는 5만 남습니다. 이걸 코드로 구현해 보겠습니다.
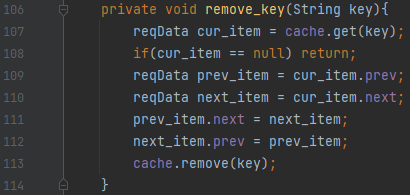
remove_key 메소드를 봅시다. 우리는 key에 대응되는 node를 뽑습니다. 이 node가 제거할 노드가 되겠네요. 이 원소 이전 원소를 prev_item, 다음 원소를 next_item이라고 할 때, 아래와 같이 정보를 업데이트 해 주면 됩니다.
- prev_item의 다음 원소는 next_item이다.
- next_item의 이전 원소는 prev_item이다.
다음에 cache에서 key를 제거해 주면 됩니다.

이제, remove_oldest를 봅시다. head의 다음 원소가 가장 오래된 원소이니, head.next.key를 얻어와서 제거하면 됩니다. 제거해야 할 key는 이것이니 이것을 remove_key의 인자로 넘겨주면 됩니다. 여기까지 구현했으면, access 메소드는 일도 아닙니다.
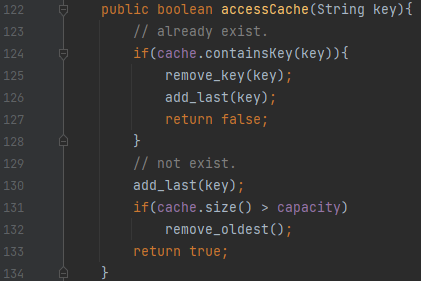
키가 이미 있다면, key를 제거하고, 다시 맨 마지막에 key를 추가합니다. 없으면, 맨 마지막에 key를 추가하고, cache의 size를 검사합니다. 이것이, capacity보다 크다면 가장 오래된 원소를 제거합니다. 해당 코드는 여기서 보실 수 있습니다.
여기까지 정리해 봅시다. 우리는 java linkedhashmap 의 대략적인 원리를 이 글에서 파악하였습니다.
- value에 이전 원소와 다음 원소에 대한 정보가 추가로 들어갑니다.
- 즉 value에는 리스트의 node가 들어갑니다.
- key와 value 쌍을 hashMap 등에 저장한다면, key값을 가지는 노드를 빠르게 찾을 수 있습니다.
그리고 hashmap 클래스만 이용해서 직접 구현도 해 보았습니다. lru도 순서가 중요합니다. 순서 정보를 list에 저장하고 있었기 때문에, 충분히 구현할 수 있었습니다.