java의 linkedHashMap을 이용하면 lru cache를 쉽게 구현할 수 있습니다. python도 비슷한 클래스인 orderedDict를 제공하는데요. 만약에 그러한 것이 없다면 어떻게 해아 할까요? 몇 가지 방법이 있습니다.
- monotone queue + hashmap [현재글]
- linkedlist + hashmap (순서를 유지하는 HashMap)
- hashmap 2개
java에서 2번째 방법으로 구현하려면 custom하게 link를 관리해야 하는 귀찮음이 있습니다. 이 글에서는 lru 알고리즘 monotone queue 자료구조와 hashmap을 사용하는 1번째 방법으로 구현해 보도록 합시다.
lru 알고리즘
먼저 lru 알고리즘을 시뮬레이션 해 봅시다. cache의 크기는 2라고 해 보겠습니다.
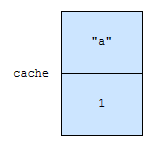
“a”가 cache에 추가됩니다. 이 때, “a”의 access time은 1이 됩니다.
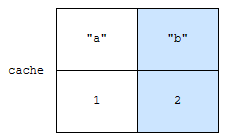
다음에 “b”가 추가됩니다. “b”의 access time은 2가 됩니다. 여기까지는 map 하나로만 관리하면 별 문제가 없습니다. 이 다음이 문제입니다.
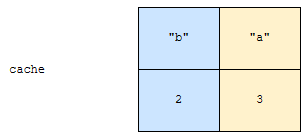
“a”에 접근했습니다. 그러면, “a”의 access time은 1에서 3으로 업데이트 되어야 합니다. 이 부분은 어렵지 않습니다. 그 다음 상황이 문제입니다. 가장 접근을 오랫동안 하지 않은 노드를 어떻게 빠르게 찾을까요?
LinkedHashMap은 이를 LinkedList로 처리했습니다. 이것은 오래 동안 접근하지 않은 것이 양 끝단 중 하나에 있습니다. 그런데, 이를 Queue로도 처리할 수 있습니다.
- 오랫동안 접근을 하지 않았다는 것은 먼저 추가된 데이터입니다.
- 먼저 추가된 것이 먼저 나온다는 특성은 Queue의 특성과 유사합니다.
여기에 몇 가지만 추가하면 lru 알고리즘을 구현할 수 있어요.
의미 없는 정보 지우기
queue에는 아래와 같은 정보만 저장합니다.
- key가 시각 time에 접근되었다.
즉, “a”가 시각 1에 추가되고, 2에 접근하고 되고, 3에 또 접근했다면, 3개의 정보가 저장됩니다.
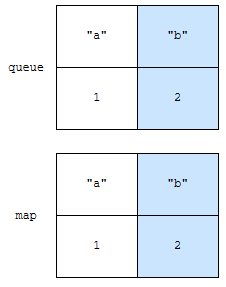
2개의 자료구조를 선언합니다.
- map
- key와 마지막 접근 시간을 저장합니다.
- queue
- key가 접근했던 이벤트들을 모두 저장합니다.
이 둘이 어떤 차이가 있는지 보도록 하겠습니다.
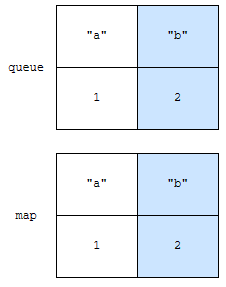
“a”가 시각 1에 추가되고, “b”가 시각 2에 추가되었습니다. 다음에 “a”를 시각 3에 접근해 보겠습니다.
map에는, 키의 마지막 접근 시각만 가지고 있어야 하므로, “a”의 마지막 접근 시각은 3이라는 정보로 업데이트 합니다. queue에는 “a”의 접근 시각이 3이다라는 정보를 뒤에 추가합니다. 맨 앞에 “a”에 접근한 시각은 1이라는 정보는 무효화가 된 건데, 바로 제거할 필요가 없습니다.
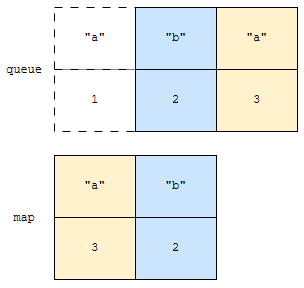
이렇게 되면 이벤트가 발생한 시각 오름차순으로 정렬되게 됩니다. monotone queue 의 특성을 가지게 됩니다. 이제 키 “c”가 시각 4에 추가되었다고 해 보겠습니다.
그러면 가장 오랫동안 접근을 하지 않은 “b”를 제거해야 할 건데요. 어떻게 처리할까요? 일단, queue에는 이벤트가 발생한 시각 오름차순으로 되어 있습니다. 따라서, 맨 앞에는 오래된 이벤트가 있을 겁니다. 이것부터 탐색합니다.
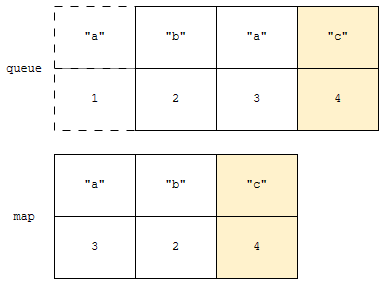
queue의 맨 앞 정보는 “a”에 시각 1에 접근했다입니다. 그런데, map에는 “a”에 시각 3에 접근했다입니다. 두 시각이 맞지 않아요. 이 말은, queue에 있는 정보가 유효하지 않다는 것입니다. 따라서, queue에 있는 정보만 제거합니다.
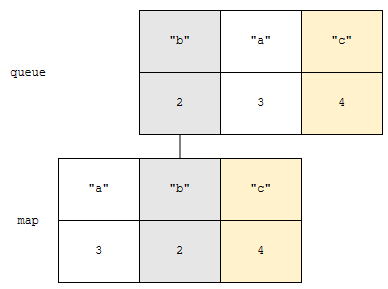
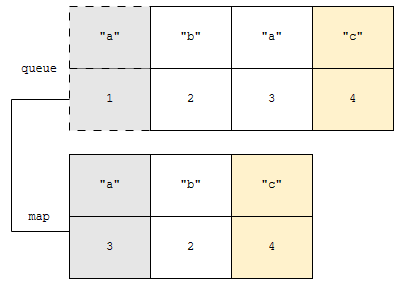
다음, queue의 맨 앞에는 “b”에 시각 2에 접근했다는 정보가 있습니다. map에도 역시, “b”에 시각 2에 접근했다는 정보가 있네요. 두 정보가 같네요. 따라서, 맵과 queue에 “b”에 대한 정보를 제거합니다. 이 아이디어는 제가 이 문제와 이 문제로 출제한 적이 있으니 알아두시면 좋습니다. 특히 후자는 완벽하게 모노톤 큐로 접근하는 방법이 있으니 익혀두면 매우 좋겠습니다.
코드 보기
이제 코드를 보겠습니다.
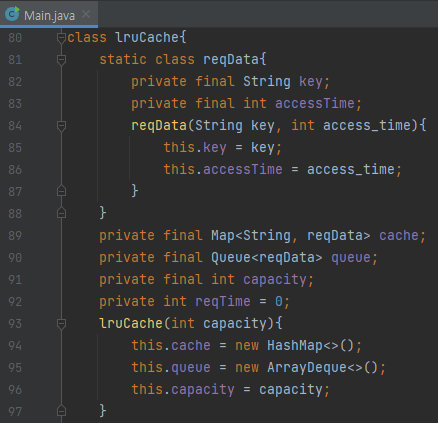
먼저, lruCache 클래스의 필드들을 보겠습니다. reqData라는 내부 클래스가 있는데, key와 마지막 접근 시각을 저장합니다. 필드들은 아래와 같습니다.
- cache
- 실제 cache에 저장되어 있는 데이터를 의미합니다.
- queue
- key가 time에 접근되었다는 정보를 들고 있는 자료구조입니다.
- 오래된 것이 맨 앞에 있어야 하니, queue가 적합합니다.
- capacity
- cache의 용량입니다.
- reqTime
- 접근 이벤트가 들어올 때 마다 하나씩 증가하는 변수입니다.
다음에 메서드들을 보겠습니다.

이 메소드는 cache에 없어서 추가했다면 true를, 이미 있었다면 false를 돌려줍니다. 여기서 중요한 것은, cache에는 put을 호출했고, queue에는 add를 호출했다는 것입니다. 이 둘은 데이터가 이미 있을 때 차이가 있습니다.
- cache의 put은 데이터가 있을 때, 정보를 업데이트합니다.
- queue의 add는 데이터가 있을 때에도 정보를 맨 뒤에 추가합니다.
다음에 이미 캐시에 추가한 후, cache의 크기가 capacity보다 큰 경우, remove_oldest를 호출합니다. 이 메서드를 보겠습니다.
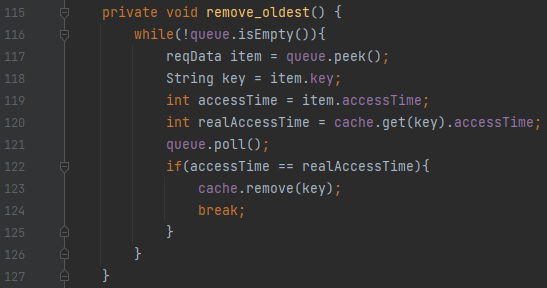
여기서 보아야 할 것은, 119 ~ 120번째 줄과, 122번째 줄의 break 조건입니다. 여기에서는 cache에서 가장 오래된 것 하나만 제거하면 됩니다. 따라서 아래와 같은 로직을 수행해야 합니다.
- invalid한 정보는 계속 제거합니다.
- valid한 정보가 나오면, cache와 queue에서 해당 정보를 제거하고 break 합니다.
valid한 정보를 판단하는 기준은 무엇일까요? queue에 있는 key에 접근한 시각 정보와, cache에 있는 key에 접근한 시각 정보가 같은 것입니다. 이렇게 lru 알고리즘 구현을 monotone queue와 hashmap으로 구현해 보았습니다. 1
- 여담이지만, 이벤트 기반 시뮬레이션은 제가 자주 낸 유형입니다. ↩︎