c++ lower_bound upper_bound 함수는 해당 키보다 작지 않은 최초의 위치, 해당 키보다 큰 최초의 위치를 돌려줍니다. 당연하게도, 정렬이 되어 있어야 제대로 동작하므로, 정렬을 해 주어야 합니다. key보다 작다. key보다 크다의 의미가 애매하실 겁니다. 이에 대해서 먼저 언급하고 넘어가도록 하겠습니다.
key 비교하기
정렬을 한다면, 두 key 간의 비교를 하게 됩니다. 보통은 그렇습니다. 예를 들어, 사람에 대한 데이터가 있는데요. 키와 이름이 있어요. 그런데, 키는 오름차순으로, 키가 같다면, 이름 사전순으로 정렬하고 싶단 말이지요. 그렇다면
- 키가 작은 쪽
- 키가 같다면 사전순으로 앞선 쪽
이 작은 쪽이 됩니다. 이 기준으로 sort 했다고 했을 때, 아래 두 키를 볼까요?
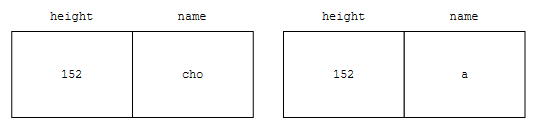
어느 key가 더 작을까요? 이건, 정렬했을 때 어느 key가 앞에 오는지를 따져 주면 됩니다. 아까 뭐라고 했나요? 키가 작은 순, 키가 같다면 이름 사전순이라고 했습니다.
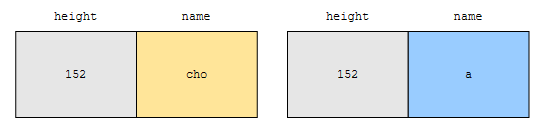
키는 같네요. 그런데 name이 어느 쪽이 더 작나요? 사전순으로 앞선 순은 뒤에 것입니다. ‘a’가 ‘cho’보다는 사전순으로 앞서기 때문입니다. 따라서, 뒤의 key가 앞의 key보다 작다고 할 수 있어요. 만약에, 두 키가 같으면 어떨까요?
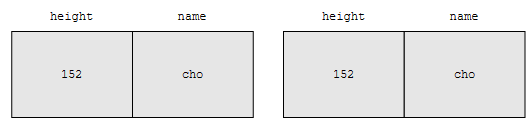
이 경우, 두 key가 같은 상황입니다. 즉 무슨 말인가?
- 앞의 key는 뒤의 key보다 작지 않습니다.
- 뒤의 key는 앞의 key보다 작지 않습니다.
이 말과 동치입니다. 여기까지 이해하셔야 해요. 정리하면 키 a가 b보다 작지 않다는 이야기는
- a와 b가 같거나
- key a와 b가 같지 않다면, 정렬했을 때 a가 b보다 뒤에 온다.
이 둘 중 하나를 의미합니다. 여기까지 이해하셨다면 본론으로 들어가겠습니다. 당연하게도 비교 기준에 따라 달라진다는 것 조심하세요.
c++ lower_bound upper_bound 사용하기
두 함수는 사용하는 것이 그렇게 어렵지 않습니다. 인자와 리턴값 부터 이해해 보겠습니다.
- iterator start
- iterator end
- [start, end)까지 탐색합니다. start는 포함하고, end는 포함하지 않습니다.
- 벡터 v를 정렬했다면, start에 v.begin()을, end에 v.end()를 넣는 경우가 많습니다.
- value
- comp
- key를 비교할 기준을 의미합니다.
이렇게 4개의 인자를 넣어서 넘겨주면, 최초의 위치값을 iterator로 돌려주게 됩니다. 몇 개의 예제를 보면서 이해해 봅시다.
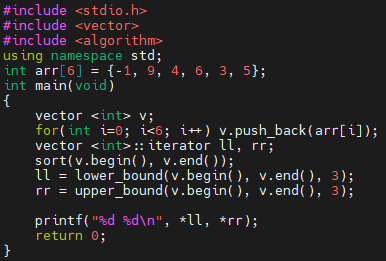
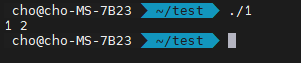
먼저, 예제 1번입니다. int의 경우, 기본적으로 오름차순으로 정렬하게 됩니다. sort 함수가 수행되고 나면, 벡터에는 -1, 3, 4, 5, 6, 9 순으로 정렬되어 들어갔을 겁니다.
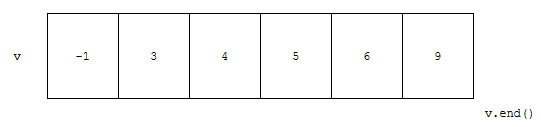
정렬이 요래 된 상황입니다. 그리고, lower_bound, upper_bound의 cmp에도 아무 것도 없습니다. 이 경우, 크기가 작은 수가 작은 쪽이 됩니다. 그러면 아래 둘을 해석해 봅시다.
- lower_bound 3
- 3보다 작지 않은 최초의 위치래요.
- 그러면 3보다 같거나, 큰 것들 중 최초의 위치를 찾는다는 의미입니다.
- upper_bound 3
- 3보다 큰 최초의 위치래요.
- 그러면 3보다 큰 최초의 위치를 찾습니다.
그러면, c++ lower_bound 함수와 upper_bound는 아래와 같이 찾을 겁니다.
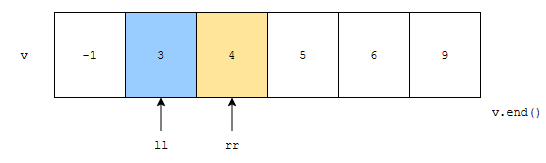
ll은 3을 가리키고, rr은 3보다 큰 최초의 위치 4를 가리킵니다. 결과가 어떻게 나올까요?

결과는 위와 같습니다. 위치를 리턴했기 때문에 역참조 연산자 *로 실제 값을 얻어왔다는 것을 보시면 됩니다. 그런데, 이 정보가 그닥 유용한 정보가 아닐 때도 있습니다. 우리는 몇 번째의 위치에서 최초로 나오는지를 얻고 싶어요. 이 경우, 어떻게 하면 될까요?
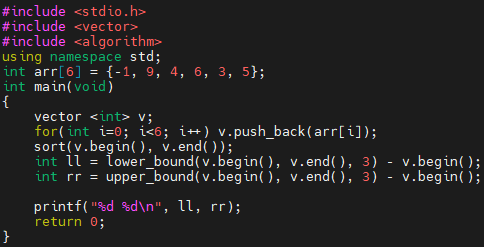
예제 2번 프로그램은, 3보다 크거나 같은 최초의 위치값, 3보다 큰 최초의 위치값을 얻어옵니다. 여기서 중요한 것은 iterator끼리 빼 버렸다는 것인데요. lower_bound의 리턴 값에 v.begin()을 빼 버렸습니다. 그리고, upper_bound의 리턴 값에 v.begin()을 빼 버렸습니다. 이 경우, 상대적인 위치 값을 돌려주게 됩니다.
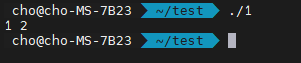
결과는 위와 같습니다. 아까와는 다르게 1, 2가 나옵니다. 좌표 압축에서 심심찮게 쓰이기 때문에 ps를 하신다면, 이디엄처럼 알아두셔야 합니다.
cmp 간단하게 이용하기
cmp는 비교 기준을 의미한다고 했습니다. 어떻게 사용하는지, 예제를 볼게요.
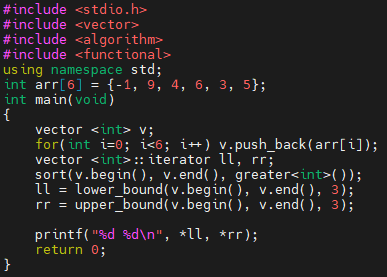
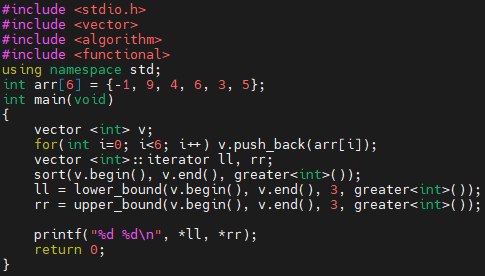
예제 3번 프로그램은, 내림차순으로 정렬한 다음에, lower_bound, upper_bound를 사용합니다. 그런데, lower_bound와 upper_bound 함수에서 따로 compare를 정의하지 않았네요? 즉, 정렬할 때 비교 기준과, 탐색할 때 비교 기준이 다릅니다.
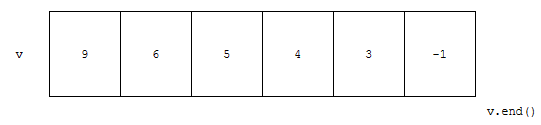
이 배열에서 이진 탐색을 할 것인데요. 키가 작은 쪽이 더 작습니다.
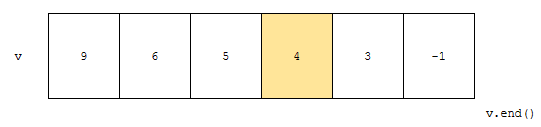
찾으려는 키가 3입니다. 그런데, mid가 가리키는 값이 4입니다. 3 < 4인가요? 찾으려는 키가 mid가 가리키는 것보다 작으므로, 왼쪽으로 갑니다.
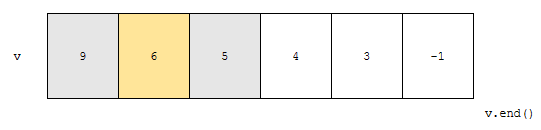
이제, mid가 가리키는 key는 6입니다. 3 < 6이므로, 찾으려는 키가 mid보다 작습니다. 따라서, 왼쪽으로 계속 가겠지요. 그러면, 3보다 큰 최초의 위치는 9, 크거나 같은 최초의 위치는 9다. 라는 결과가 나올 거에요.
그런데 보세요. 정렬의 기준은 내림차순이였어요. 즉
- key가 클수록 더 작습니다.
- 즉, 3보다 크거나 같은 최초의 위치를 찾는다는 의미는
- 3과 같거나
- 3보다 내림차순으로 더 뒤에 오는 최초의 위치를 찾아야 하는데 그게 아니였습니다.
왜? 탐색 비교 기준과 정렬 비교 기준이 달랐기 때문입니다.
이제 탐색 비교 기준과 정렬 비교 기준을 맞춰봅시다. greater<int>()로 맞춰주었음을 볼 수 있어요. 이 경우 어떻게 탐색할까요?
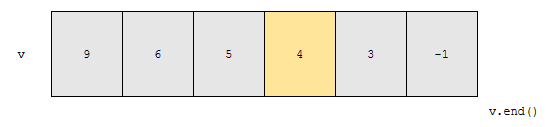
mid 값인 4와, 찾으려는 값 3을 비교합니다.
- 내림차순에서는 찾으려는 값 3이 mid 값인 4보다 큽니다.
- 탐색 비교 기준도 내림차순이기 때문에 오른쪽에서 탐색하게 됩니다.
정확하게 탐색하게 됩니다.
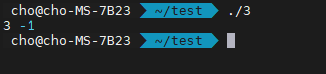
4번 프로그램의 결과는 위와 같습니다. 정리하면, 정렬의 비교 기준과, 탐색의 비교 기준을 맞춰야 한다는 것입니다. 그래야, 의도한 대로 결과가 나오게 됩니다.