동점자가 있는 경우에 대해, postgres dense_rank 함수와 rank 함수는 처리 방식이 달라요. 이 글에서는 이에 대해 알아보도록 합니다.
- rank 함수
- dense_rank 함수 [현재글]
당연하게도, rank와 사용법이 같기 때문에, 사용법은 따로 설명하진 않겠습니다.
rank 함수가 랭킹을 계산하는 방식
모든 사람의 점수가 다를 때 rank는 별 문제가 되지 않습니다. 문제는 동점자가 있을 경우입니다. 랭크 값이 같을 경우입니다. rank 값은 랭킹을 매기는 기준의 값으로 결정되게 되는데요. 예를 들어, 점수 내림차순으로 랭크를 매긴다고 하면
- 랭크를 판단하는 기준이 되는 값은 점수입니다.
- 점수가 높을수록 rank 값이 높습니다.
여기까지 이전 글에서 설명을 했었습니다. 동점자가 있는 경우, rank는 어떻게 처리될까요? 예를 들어, 점수가 아래와 같다고 해 보겠습니다.
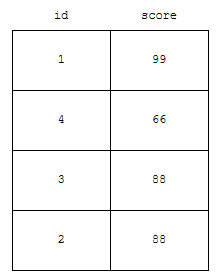
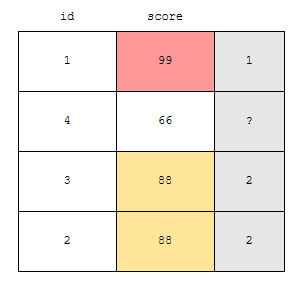
id가 1인 사람의 점수는 99점입니다. 4인 사람은 66점이고, 2와 3인 사람은 88점입니다. 동점자가 있어요. 이 때, score를 기준으로 내림차순 랭킹을 매긴다고 하면 어떻게 나올까요? rank 함수는
- 자기보다 rank가 높은 결과의 수 + 1
로 합산이 됩니다. 그러면, 점수가 66점인 사람의 경우, 자기보다 점수가 높은 사람은 id가 1, 2, 3인 사람 이렇게 3명입니다. 결과가 3개 잖아요? 따라서, rank는 3에 1을 더한 4가 되겠습니다.
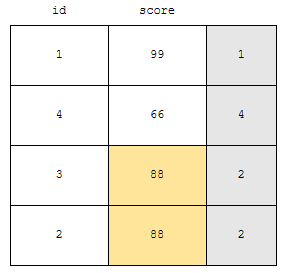
우리는, 99점의 1번과, 노란색으로 표시된 2, 3번이 점수가 66점인 사람보다 높다는 것을 보아야 합니다. 따라서, rank는 1번이 1, 2와 3번이 2, 4번이 4라고 할 수 있습니다. 그러면, dense의 특징을 가지나요? dense는 빽빽한, 밀집 이라는 뜻을 가지고 있어요.
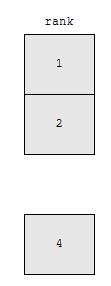
그런데 보세요. rank가 3인 것이 없어요. 3인 것이 누락되어 있으니까, 밀집된 것이 아닙니다. 따라서, sparse 정도까진 아니지만, dense는 아닌 셈입니다. 동점자가 있으면 누락된 랭크가 있는 것이 rank 함수의 특성이라고 할 수 있습니다.
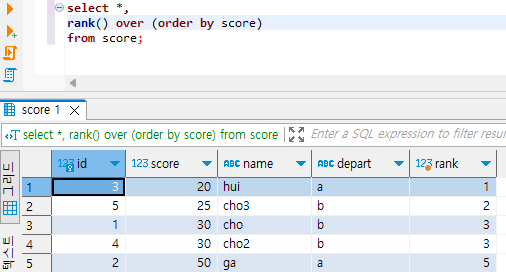
이제, rank 함수의 실행 결과를 볼게요. order by score 라고 하였으니, 점수 오름차순으로 랭킹을 매깁니다.
- 점수가 s인 사람 입장에서는
- 점수가 s보다 낮은 사람의 수 + 1 이 자신의 rank가 됩니다.
그러면, 점수가 30인 사람의 rank가 3인 것은 이해가 갑니다. 왜? 20과 25점을 받은 사람 2명이 자기보다 점수가 낮기 때문입니다. 점수가 50인 사람의 rank는 왜 5일까요?
- 점수가 50인 사람은
- 점수가 50보다 낮은 사람의 수 + 1이 rank가 되기 때문입니다.
점수가 50보다 낮은 사람의 수는 4명이고 여기에 1을 더하면 5가 됩니다. 따라서, 5가 답이 됩니다.
dense_rank 함수
그러면, postgres dense_rank 함수는 어떻게 rank를 매기는가? dense가 밀집한, 빽빽한. 이라는 뜻을 가지고 있습니다. 그렇다면 rank에 누락이 없다. 이 정도로 해석해도 됩니다. 그러면 어떻게 매기는가?
- 자신의 rank값을 r이라 했을 때, r 보다 높은 rank 값의 수 + 1
요래 매깁니다. rank가 같은 결과가 여러 개 나오더라도, rank 값을 count 하기 때문에, 누락되는 rank가 없습니다.
그러면 위 데이터에서 점수 내림차순으로 랭킹을 매길 때, 66점을 받은 사람의 dense_rank를 구해 봅시다. 자기보다 rank가 높은 점수의 수를 구해 봅시다. 우리는 score가 높은 순으로 rank를 매기고 있어요. 따라서, rank 값은 score가 높을수록 높겠지요. 66보다 높은 점수는 99, 88 이렇게 2개입니다.
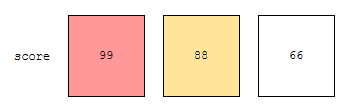
이를 좀 더 쉽게 표현하면 위와 같습니다. 99, 88, 66. 그러면, 66보다 높은 점수의 수는 2개입니다. 여기에 1을 더한 값이 66점을 받은 사람의 dense_rank가 됩니다.
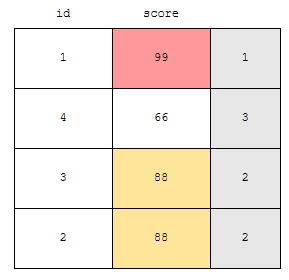
따라서, dense_rank() over (order by score desc)를 실행한 경우, 결과는 위와 같이 나오게 됩니다. 이제, 예제 쿼리를 볼게요.
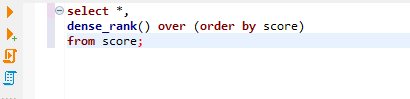
쿼리의 결과가 어떻게 나올까요? score를 기준으로 rank를 매기는데요. 오름차순으로 매기고 있지요?
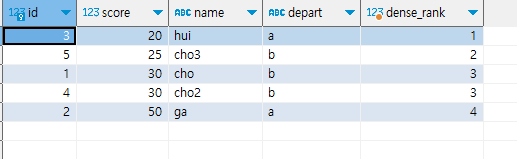
이 경우, 20, 25, 30은 크게 어렵지 않습니다. 1, 2, 3등이기 때문입니다. 문제는 50점을 받은 사람인데요.
- rank는 score가 낮을 수록 높습니다.
- 따라서, 50보다 rank가 높다는 것은, 50보다 점수가 낮다는 것입니다.
- score가 50인 것 보다 rank가 높은 것은 20, 25, 30 이렇게 3개입니다.
따라서, 점수가 50인 사람은 dense_rank가 3 + 1의 값인 4가 나오게 됩니다. 정리하면, rank 함수는 랭크가 높은 결과의 수로 합산하는 반면에, postgres dense_rank 함수는 랭크가 더 높은 rank 값의 수로 합산한다는 것이 다릅니다.