sql 에는 union 과 union all 문이 있습니다. 이 둘의 차이점을 알아보고, 코딩 테스트에 나올 만한 몇 가지 예제 쿼리를 작성해 봅시다.
sql union
먼저, union과 union all의 차이를 먼저 정리해 봅시다.
- union 은 결과를 append 하는데, 중복되는 결과는 제거합니다.
- union all 은 중복되는 결과도 그대로 append 합니다.
예제 쿼리를 몇 가지 보겠습니다.
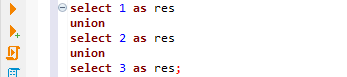
1번 쿼리를 봅시다. select 1 as res는, 속성값 res가 1인 레코드만 나오게 합니다. select 2 as res는 속성값 res가 2인 레코드만 나오게 합니다. select 3 as res는 res가 3인 레코드만 나오게 합니다. 이 셋을 합치면 어떻게 될까요? 1과 2와 3은 다르기 때문에 3개의 결과가 나오게 됩니다.
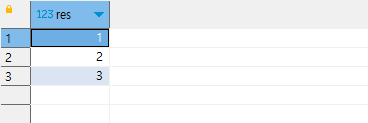
1, 2, 3이 나왔음을 알 수 있습니다.

이제, 2번을 보겠습니다. 아까와 다른 점이 있습니다.
- res 속성 값이 1, 2, 1인 것을 모두 합칩니다.
- 속성 값이 3인 것 대신에 1인 것을 union 처리합니다.
결과가 어떻게 나올까요? 1과 2는 다르지만, 2와 1은 같습니다. 따라서 1과 2 2개의 결과가 나오게 됩니다.
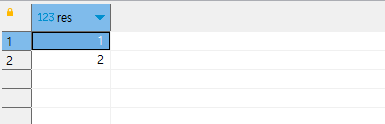
결국 중복된 1은 자동으로 제거되었음을 알 수 있습니다. 반면 union all은 어떨까요?

union 대신에 union all을 사용했습니다. 1과 2와 1을 합치는데요. 결과는 아까와 같을까요? all 은 중복된 것도 모두 나오게 합니다. 따라서, 3개의 결과가 나오게 됩니다.
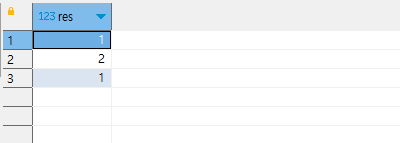
res가 1인 결과가 2번 나왔습니다. 이것이 all이 붙고 안 붙고 차이점입니다.
특정 column의 중복만 제거하기
sql union 문을 이용해서, 특정 column의 중복을 제거하고 싶습니다. 예를 들자면
- book table 에는 장르와 책 이름이 있습니다. 이 때
- 모든 장르를 출력합니다.
- 그런데, 장르 하나에, 책 하나만 출력합니다. 아무것이나.
이런 요구 사항이 들어온 경우 어떻게 처리해야 할까요? 아래와 같은 아이디어는 어떨까요?
- 일단 모두 union을 합니다.
- 결과 셋에서 distinct 처리합니다.
postgres 에서는 이렇게 처리 할 수 있습니다. 도식화 시켜 볼까요?
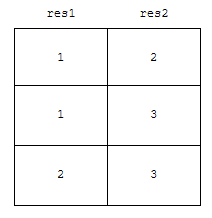
먼저, union 으로, 결과 set을 모두 얻어옵니다. 이를 from 절의 sub query로 처리합니다.
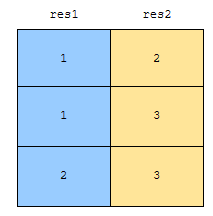
다음에, distinct의 중복 조건에 걸리는 column과 그렇지 않은 컬럼을 select distinct 절에 적어줍니다. 예를 들어, 군청색으로 표시한 res1은 distinct의 중복 조건에 걸리고, res2는 걸리지 않는 경우, 아래 쿼리로 처리할 수 있습니다.

postgresql에서는 distinct on 을 이용하면 됩니다. 이 때 on에는 어떤 컬럼이 중복되면 제거할 것인지를 넣습니다.
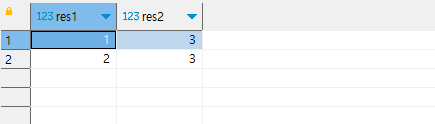
쿼리의 결과는 위와 같습니다. 그런데, distinct on 은 postgres 특정 문법입니다.
with 절과 join 을 이용하기
mysql과 같은 다른 db의 경우, with 절과 join을 이용해야 합니다. 이 때, 2가지 idea를 이용합니다.
- 각 table 마다 pk가 하나씩 있다.
- 결과를 with 절에 임시로 정의해 놓으면 쿼리를 줄일 수 있다.
이 아이디어로 접근해 볼까요?
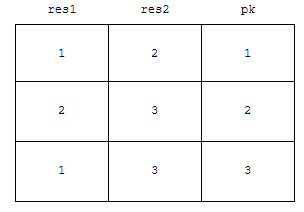
먼저 with 절을 정의합시다. 여기서 중요한 것은 pk 역할을 하는 column 까지 같이 얻어와야 한다는 것입니다. 다음에, distinct 중복 조건에 걸리는 res1 을 기준으로 group by를 한 테이블을 만듭시다.
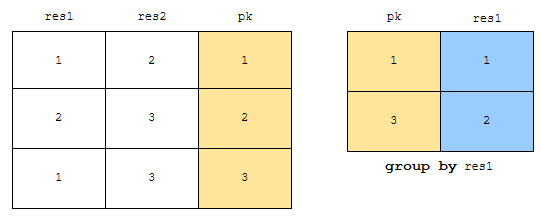
이 테이블은 그림의 오른쪽에 있어요. 그러면, 두 테이블이 만들어 졌지요. 이제, 이걸 어떻게 하면 될까요? pk를 기준으로 inner join 시키면 됩니다. 이 아이디어를 적용한 쿼리를 보겠습니다.
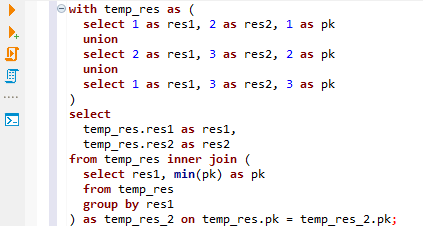
temp_res는 왼쪽의 테이블, temp_res_2는 왼쪽의 임시 결과를 res1 로 group by를 한 것입니다. 이 둘을 inner join을 하면, 중복된 res1은 제거됩니다.
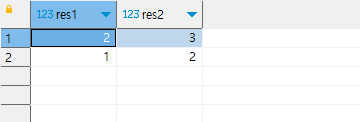
결과는 위와 같습니다.