java에서 tokenize를 할 때 두 개의 방법을 많이 씁니다.
- string tokenizer
- split 메소드
이 둘에 대해서 비교하겠습니다.
string tokenizer의 내부 동작
string tokenizer는 delimeter를 넘겨준다고 했습니다.
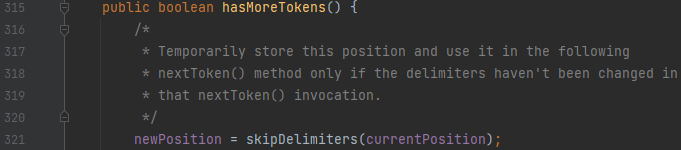
먼저, hasMoreTokens로 토큰이 있는지를 검사한다고 하였습니다. 여기서 skipDelimeters를 주목해 주세요.
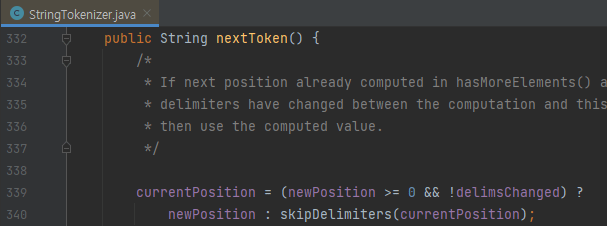
다음, nextToken을 봅시다. 두 메서드에서 공통으로 보이는 것이 무엇인가요? skipDelimiters를 호출하는 것을 볼 수 있어요. 이 함수의 내부로 들어가 봅시다.
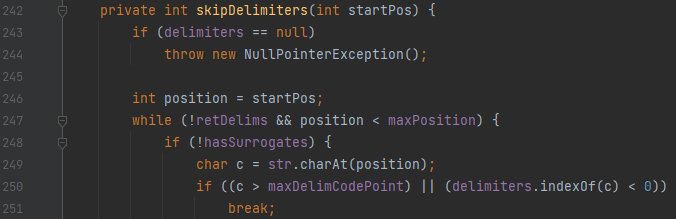
[그림 3]에서 보아야 할 것은 딱 2개입니다.
- 249번째 줄의 charAt(position) 부분
- 250번째 줄의 delimeters.indexOf(c) 부분
하나씩 봅시다. 먼저, charAt(position)을 봅시다. 이 메소드는 position 번째에 있는 문자를 가져오는 역할을 해요. 자바는 String 또한 배열로 구현되어 있어요. 그러면 3번째에 있는 문자는 어떻게 가져와요?
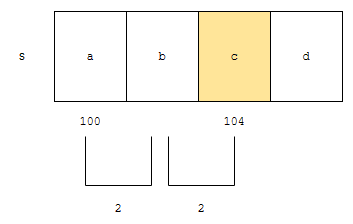
배열은 크기가 같은 원소들이 연속으로 모여있는 집합이라 했어요. 기준 위치 알고, 원소 당 크기를 아니까, 상대적인 위치도 금방 계산이 됩니다. 아래 글들에서도 설명을 했어요.
고로, 매우 효율적으로 동작합니다. 문제는 indexOf 입니다. delimeter에 c가 있는지 검사하는데요.
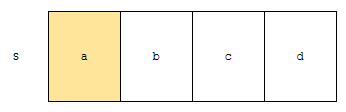
“abcd”에서 ‘a’를 찾는 연산은 상당히 빠르게 동작합니다. 왜? 1번째 위치에 바로 문자 a가 있기 때문입니다. 하지만, ‘e’를 찾는 건 어떨까요?
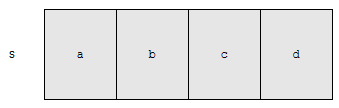
문자열 전체에 대해서 탐색해 보고 없다고 해야 합니다. 따라서, 최악의 경우 250번째 줄에서 delimeter 문자열의 길이만큼의 복잡도를 가질 수 있어요. 매번 target string의 문자 각각에 대해서요. 이 말은 다시 말하면
구분자가 매우 많은 경우 stringTokenizer는 매우 불리합니다.
target 문자를 순회할 때 마다, delimeter 문자열 전체를 보기 때문입니다.
보통, 구분자의 경우가 많지 않기에, string tokenizer를 써도 무방합니다.
java split 와 string tokenizer 성능 테스트
java split는 regex를 받기 때문에
- tokenizer 보다 복잡한 조건에 대해서 적용 가능합니다.
- 다만, 저의 경우 split 또한
- 특정 문자를 기준으로 토큰화 하는 경우에 많이 씁니다.
- 따라서 regex 또한 문자 집합을 의미하는 []가 들어갔습니다.
그러면 실험을 해 봅시다. 먼저, 테스트를 위한 buildForTest 메소드입니다. 이 메소드에서 쓰는 변수는 3개가 있는데요. 각각에 대한 설명은 아래와 같습니다.
- target은 토큰화를 시킬 문자열을 의미합니다.
- delimiter는 string tokenizer class에 넣을 delimeter를 의미합니다.
- splitPattern은 split에 넣을 정규식을 의미합니다.
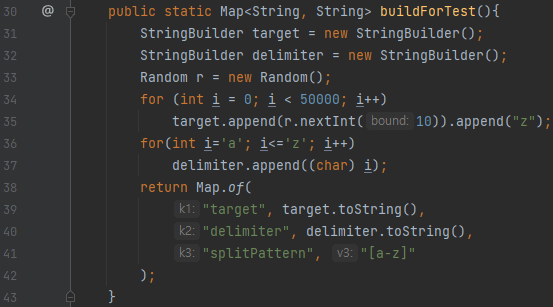
1번 테스트에 쓸 데이터입니다. 소문자 집합이 구분자 집합이 됩니다. 그리고, 구분자는 총 5만개를 넣었고, 구분자 사이에 1부터 10까지의 수 중 랜덤하게 넣어놓았습니다.
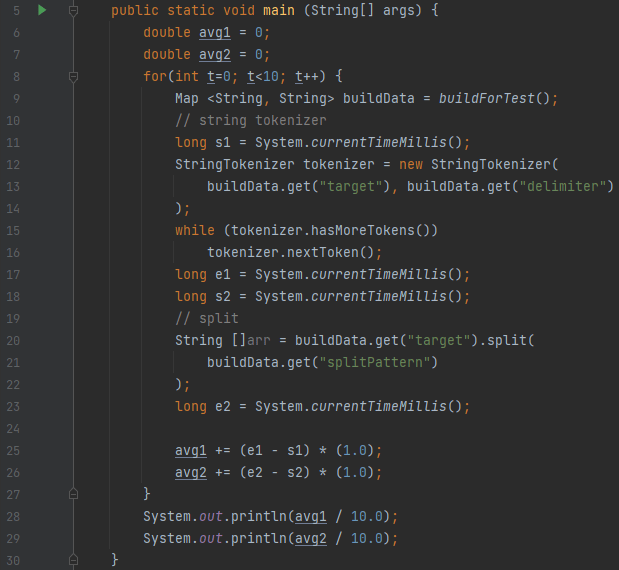
이렇게 세팅된 데이터를 가지고, StringTokenizer와, split의 시간을 측정합니다. 10번 측정해서 나온 평균 시간을 측정하는데요.
- 1번째로 나온 결과는 String Tokenizer가 평균적으로 걸린 시간
- 2번째로 나온 결과는 split이 평균적으로 걸린 시간
을 의미합니다.
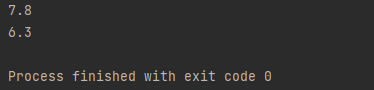
결과를 볼까요? 전자는 7.8, 후자는 6.3이 걸립니다.
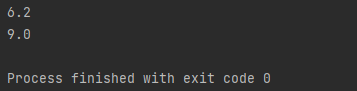
심지어 어떤 경우에는 전자보다 후자가 더 걸리는 경우도 있어요. 이는, split의 경우 내부적으로 정규식으로 파싱하기 위한 정보를 추가로 만들기 때문이에요. 문자 집합이 26개여서, split보다 string tokenizer가 월등히 오래 걸릴 거 같았지만, 그렇지 않았던 이유는, 이 정보를 만드는 작업이 가볍지 않았기 때문입니다. 1
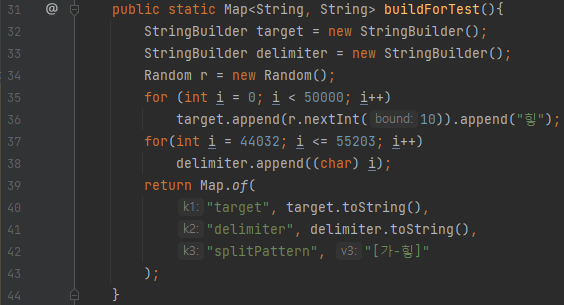
반대로, 구분자가 매우 많은 경우에는 이야기가 달라집니다. 44032는 ‘가’, 55203는 ‘힣’을 의미하는데요. delimeter에 가부터 힣까지 다 넣습니다. 그러면 구분자 문자열의 길이가 1.1만자가 넘겠지요. 즉, target 문자열을 token화 시킬 때, 문자 하나 하나 돌 때 마다
- 1.1만자가 넘는 delimeter에 대해 해당 문자가 있는지 검사합니다.
- 만약에, 해당 문자가 없다면, 이미 delimeter는 다 스캔한 상황입니다.
그렇기 때문에, 상당히 비효율적으로 동작하겠지요.
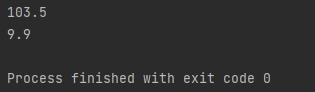
전자가 103.5, 후자가 9.9입니다. 압도적으로 전자가 느렸는데, delimeter가 상당히 크기 때문입니다. 오히려 java split 을 사용한 쪽이 압도적으로 빨랐습니다. 정리하면
- 구분자의 길이가 26 ~ 30자 내외면 string tokenizer로 분리합니다.
- 구분자의 길이가 매우 커지면
- split를 고려하거나
- target 문자열에 있는 구분자를 하나의 문자열로 치환 후 tokenizer를 쓰면 됩니다.
- 예를 들어 구분자가 한글이라면
- 한글인 문자를 모두 ‘가’로 치환한 후에
- ‘가’를 기준으로 분리하면 됩니다.
- 사실 이펙티브 자바에도 나오는 부분입니다. 쓸데없이 객체를 생성하지 말라고. ↩︎