java에서 string parsing을 하기 위해서 크게 2가지를 많이 씁니다.
- string tokenizer [현재글]
- split
이 두 개를 시리즈로 묶어서 알아볼 거에요. 이 글에서는 string tokenizer에 대해서만 다룹니다.
java string tokenizer 기본형
먼저, 이 클래스는 토큰화를 시킬 string을 기본으로 받습니다. 추가로
- delimeter를 받게 됩니다.
- 여기서 delimeter란, 구분자로 사용될 문자들을 의미합니다.
delimeter를 쓰는 것은 확장형에서 알아볼 거에요.
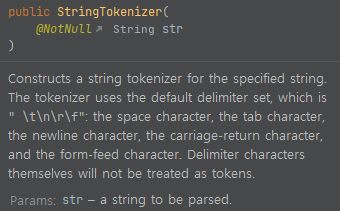
기본형에 대한 설명을 봅시다. delimeter가 아무것도 주어지지 않았는데요. 이 경우에
- 공백
- 탭
- \r, \f
- 개행 문자
이 5개가 delimeter가 됩니다. 보통, 공백, 탭 정도 구분자로 쓸 때, 해당 생성자를 쓴다고 기억하시면 편하겠습니다. white space를 구분자로 쓴다고 알고 있는 경우도 있는데, 아닙니다. white space는 이들 말고도 훨씬 많습니다. 이제 코드를 볼까요?
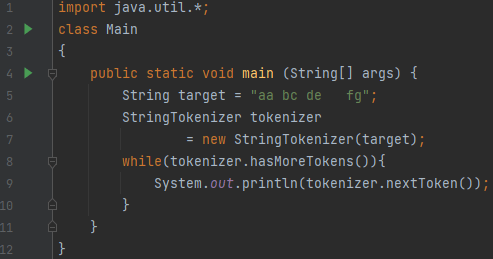
먼저, target은 “aa bc de fg”입니다. de와 fg 사이에 tab 문자가 있습니다. StringTokenizer 생성자에
- target만 넣었습니다.
- 이는, target을 토큰화 시킬 것인데
- 개행과 탭, 공백과 \r, \f를 기준으로 분리하겠다는 것입니다.
이제 8 ~ 9번째 줄을 봅시다. tokenizer에 2가지 method가 있어요.
- hasMoreTokens
- nextToken
이 둘은 무엇을 하는 것인가? 상당히 자주 보이는 패턴이기 때문에 알아두시면 좋습니다.
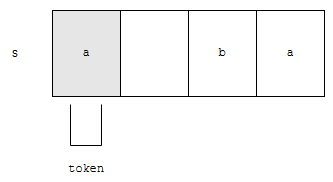
먼저, hasMoreToken은 토큰이 있는지를 검사해요. 예를 들어 공백을 기준으로 자른다고 합시다. 그리고 target이 “a bc”라고 해 보자고요. 맨 처음부터 scan을 해 봅시다. 그러면
- 공백이 아닌 문자가 a 있고 다음에 공백이 이어지네요.
- 토큰이 “a”네요.
있기 때문에 참을 돌려줍니다. 대신, 토큰을 소모하지 않습니다.
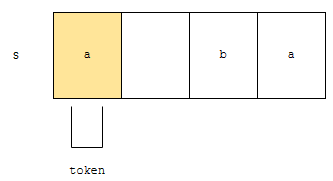
실제로 토큰을 소모하기 위해서는 nextToken 메소드를 호출해야 합니다. 다음에, hasNextToken을 호출하면 어떻게 될까요? 다시 처음부터 검사할까요? 아닙니다.
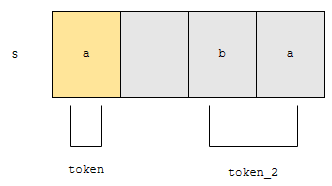
토큰으로 끊어진 위치 다음부터 검사합니다. 그리고 “bc”라는 token_2를 찾아냅니다. 토큰이 있었으므로, hashNextToken은 참을 리턴합니다. 이제, 이 상태에서, nextToken을 호출하면 어떤 일이 벌어질까요?
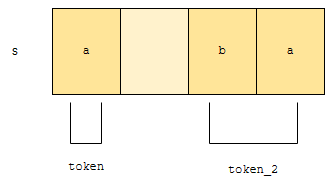
token_2까지 소모가 됩니다. 그 이후에 hasMoreToken을 호출하면, 이미 토큰들이 다 소모되었으니, 없다고 하겠네요. 이런 식으로
- 원소가 있는지를 검사하고
- 있다면 가져오는
패턴은 코딩 테스트에서도, 구현에서도 적지 않게 쓰이므로 알아두시는 편이 좋습니다.
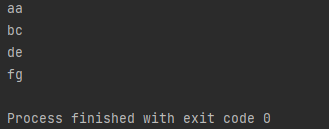
예제 1번 프로그램의 결과를 보면, aa, bc, de, fg 순서대로 나왔음을 볼 수 있습니다.
delimeter를 넣는 예제
이제, delimeter 인자를 넣어 봅시다.
delim을 넣으면, 해당 delim에 속한 문자들을 token으로 취급하지 않습니다.
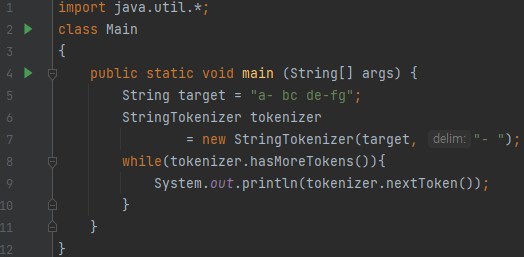
예제 2번 프로그램을 봅시다. “a- bc de-fg”가 있어요. 여기서 저는 ‘-‘과 공백을 기준으로 분리하고 싶단 말입니다. 그렇게 하려면 어떻게 해야 할까요?
- – 문자
- 공백
이 delimeter가 되어야 겠지요. 따라서, delim에는 “- “가 들어가면 됩니다. 결과를 볼까요?
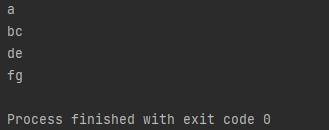
“a- bc de-fg”가 -과 공백을 기준으로 분리되어, “a”, “bc”, “de”, “fg” 이렇게 분리되었습니다. 눈치 채셨겠지만, java string tokenizer 클래스로 token화 시키는 것은, delimeter가 적을 때 유용한 방법입니다. 구분자가 매우 커지는 경우, 상당히 느려질 수 있는데요. 이는, 추후에 다시 언급하도록 하겠습니다.