postgresql에서 split_part는 구분자를 기준으로 문자열을 토큰으로 분리해 낼 수 있는 함수입니다.
사용법은 간단합니다. 1번째 인자에는 target 문자열, 2번째 인자에는 구분자 역할을 할 문자열, 3번째 인자에는 몇 번째 토큰을 뽑을 것 인지를 알려주면 됩니다. 예제를 보겠습니다.

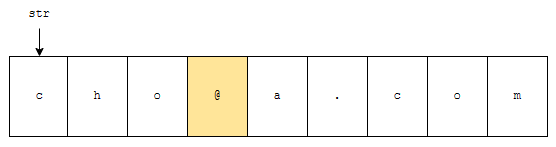
그림 1을 보겠습니다. 1번째 인자에는 ‘cho@a.com’을 넣었습니다. 이것이 target 문자열입니다. 다음 2번째에는 구분자 역할을 할 문자열이 들어가 있어요. ‘@’입니다. 다음 3번째는 토큰으로 분리된 것 중에 몇 번째 문자열을 뽑을지를 나타냅니다. ‘@’를 기준으로 분리하면 ‘cho’와 ‘a.com’으로 분리될 텐데요. 이 중, 1번째 토큰은 ‘cho’입니다.

그러므로 결과는 ‘cho’가 나옵니다.

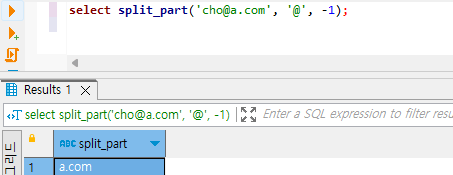
이제 쿼리 2를 보겠습니다. 쿼리 1과 다른 것은 3번째 인자입니다. 1번 쿼리는 ‘@’를 기준으로 앞쪽의 ‘cho’를 뽑아냈어요. ‘@’를 기준으로 분리했을 때, 2번째로 분리되는 것은 ‘a.com’이니, 결과는 어떻게 나올까요? ‘a.com’이 나오게 됩니다.

여기까지, 정리해 봅시다. split_part는 어떤 함수인가요? 타겟 문자열이 있을 때 특정한 구분자를 기준으로 토큰들을 분리하는 함수라는 것을 알 수 있어요. 3번째 인자에 1을 넣어주면 1번째로 분리된 토큰, 2를 넣어주면 2번쨰로 분리된 토큰, … 이런 식입니다.
3번째 인자가 음수인 경우는 어떨까요? 쿼리 3번을 보겠습니다.
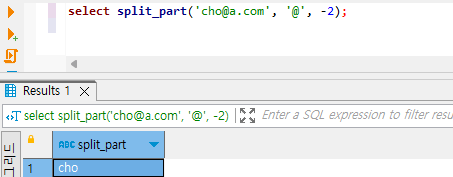
쿼리 3번은, 3번째 인자로 -2를 넣었습니다. 결과가 어떻게 나왔나요? ‘cho’가 나왔는데요. 음수가 붙으면 분리된 토큰들을 왼쪽부터 보는 것이 아니라, 오른쪽부터 왼쪽 방향으로 보게 됩니다. 이게 무슨 소리인지 도식화를 시켜 보겠습니다.
예제로 주어진 target string을 ‘@’를 기준으로 나눠 보겠습니다. 그러면 ‘cho’와 ‘a.com’으로 나누어집니다. 그러면 토큰도 ‘cho’, ‘a.com’ 순서대로 나올 겁니다. 왼쪽부터 오른쪽으로 방향으로 읽으면 말입니다. 이를 거꾸로 읽어 보겠습니다. 그러면 ‘a.com’, ‘cho’ 순으로 읽어지겠지요?
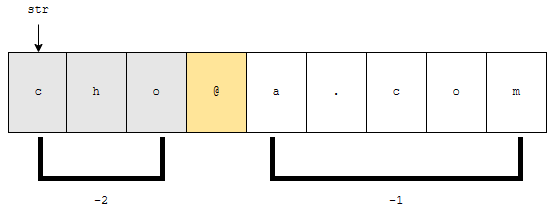
‘a.com’은 오른쪽에서 1번째, ‘b.com’은 오른쪽에서 2번째 토큰이라고 할 수 있어요. 즉, 오른쪽 n번째 token을 뽑을 때, 3번째 인자로 -n을 넣으면 됩니다. 즉, 특정 문자열을 구분자로 나눌 것인데, 그 중 마지막 토큰을 가져오고 싶다면 3번째 인자에 -1을 넘겨주면 됩니다.
이제 보너스 하나 보겠습니다. ‘cho@@a.com@@a’를 split_part 함수로 ‘@’를 구분자로 하여 분리해 봅시다.
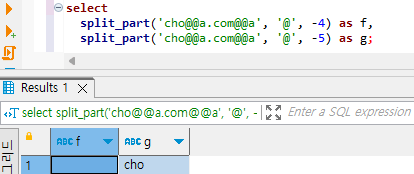
이 경우는 조금 복잡합니다. 그런데, 하나씩 도식화 시켜 보면 그리 어렵지도 않습니다. @를 기준으로 토큰을 분리할 것인데요. 구분자 사이에 빈 문자열이 와도, 빈 문자열이 분리된다는 사실을 알면 매우 쉽습니다.

그림을 봅시다. 먼저 왼쪽부터 생각해 봅시다. 구분자가 ‘@’입니다. 처음에 ‘cho’가 분리됩니다. ‘@’ 다음에 구분자가 연달아서 오게 되는데요. 구분자와 구분자 사이에 빈 문자열이 왔습니다. 따라서 2번째로 분리되는 것은 빈 문자열 ” 입니다. 다음에, ‘a.com’이 분리됩니다. 그리고 다시 구분자 2개가 오게 되는데요. 구분자 둘 사이에 빈 문자열이 온 셈입니다. 따라서 4번째에 분리되는 것은 ”입니다. 그리고 ‘a’가 오기 때문에, ‘cho’, ”, ‘a.com’, ”, ‘a’ 순으로 분리됩니다.
이걸 역순으로 보면, ‘a’, ”, ‘a.com’, ”, ‘cho’ 순으로 분리됩니다. 각각 3번째 인자에 -1, -2, -3, -4, -5를 넣었을 때 리턴되는 값입니다. 쿼리 4는 ‘@’를 구분자로 했을 때, ‘cho@@a.com@@a’가 -4, -5번째로 분리되는 토큰을 얻는 것이였습니다. ”, ‘cho’로 분리됩니다.