c언어에서 문자열의 길이를 알아낼 수 잇는 strlen 함수에 대해 알아보겠습니다.
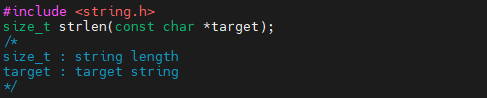
strlen 함수의 원형은 위와 같습니다. 앞에 size_t가 붙어있으니, 문자열의 길이를 돌려줍니다. 그리고, 인자로 const char *형 문자열을 하나 받는데요. char형 배열이라고 봐도 무난합니다. 예제 1번 프로그램을 하나 보도록 하겠습니다.
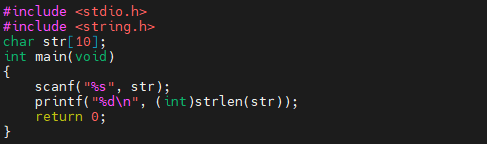
6번째 줄에, 문자열을 하나 입력 받습니다. 다음에, strlen(str)로 입력받은 문자열의 길이를 출력해요. 이것이 다입니다. 별로 어렵지 않지요? 예제를 실행시켜 보겠습니다.

dog를 입력했습니다. 결과는 어떻게 나올까요? 3이 나옵니다. 왜? d, o, g 이렇게 3글자이기 때문입니다. 그러니, 3이 나오는 것은 당연해 보입니다. 여담으로, 이 함수는 c언어의 sizeof 하고 혼동하기 매우 쉬운데요. 엄연히 다릅니다. 그림으로 간략하게 도식화 해 보겠습니다. 예제 1에서 char형 배열 str은 char형의 자료를 10개 저장할 수 있게 선언이 되었습니다.
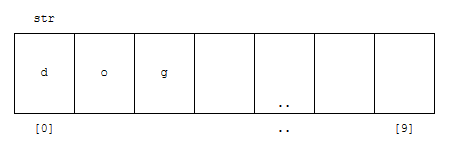
고로, sizeof(str)은 str이 할당된 크기인 10이 나오게 됩니다. 그런데, strlen의 경우, 문자열의 처음 위치부터 문자열의 끝을 나타내는 특수 문자 (널 문자)가 나타나기 전까지 카운트를 하게 됩니다. 저는 dog를 입력받았기 때문에, str에는 아래와 같이 저장이 됩니다. 회색으로 표시된 것은 문자열의 끝을 나타냅니다.

strlen(str)은, str의 위치인 “d”부터 카운트를 합니다. 다음 문자를 읽으니까 “o”가 되고, 그 다음 문자는, “g”가 됩니다. 그 다음에 회색 문자를 만나게 됩니다. 따라서, “d”, “o”, “g”만 카운트 되어서 3이 나오게 됩니다.
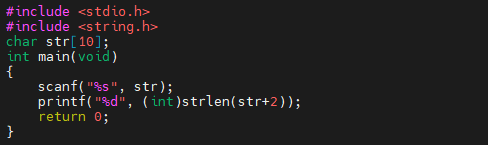
예제 2번 프로그램입니다. 다른 건 없고, 7번째 줄에 strlen(str+2)가 있습니다. 이제 2번 프로그램을 컴파일 하고 실행할 거에요. “dogafter”를 입력했을 때 실행 결과는 어떻게 나올까요?
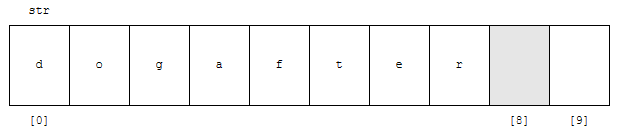
dogafter를 입력했기 때문에, str은 위와 같은 데이터들이 저장되어 있을 것입니다. 그런데, strlen(str+2)라고 하네요. 그러면 탐색 시작 지점이 str이 아니라, str+2가 됩니다. str+2는 위 그림에서 “d”가 아니라 “d”보다 2칸 뒤에 있는 “g”가 되겠습니다.

여기서부터 탐색을 하겠지요? “g”부터 문자열 끝까지 가면, “g”, “a”, “f”, “t”, “e”, “r” 순으로 잡히게 됩니다. 총 6글자입니다. 따라서 결과는 6이 나옵니다.

예상대로 dogafter를 입력하니까 6이 나왔습니다.
가희를 입력하면 어떻게 될까요? 결과가 2가 나올까요? 가, 희 이렇게 2글자이니까 2가 나올 것 같습니다.

그런데, 6이 나왔습니다. 이는 strlen이 글자 수 단위가 아니라 byte 단위로 동작한다는 것을 의미합니다. ‘가’와 ‘희’는 1byte로 표시될 수 없기 때문에 글자수와 strlen의 결과가 같지 않다는 것을 주의하시면 됩니다.