c++ algorithm에는 sort1 함수와 stable_sort가 있습니다. 이 둘에 대해서 간략하게 알아보겠습니다. 참고로, 실험 데이터는
- 원소 개수를 100개로 두었습니다.
- 이는 원소 개수를 너무 적게 두면 insertion sort2 등으로 최적화를 하기 때문입니다.
sort만 쓴 예제
먼저, sort를 쓴 예제 프로그램 1번을 보겠습니다.
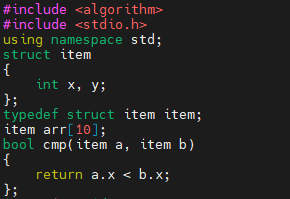
먼저, 위 코드는 1, 2번 코드에 사용할 코드입니다. item 이라는 구조체가 있는데요. x와 y 필드가 있어요. 그리고, cmp 함수가 하나 있습니다. 비교 함수를 의미합니다.
- x가 더 작은 경우, 우선 순위가 더 높습니다.
- x가 같은 경우, 우선 순위가 같습니다.
이렇게 해석하시면 됩니다.
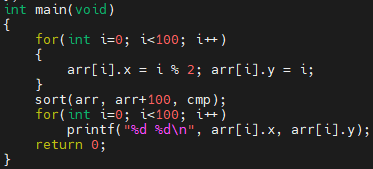
다음에, 크기가 100인 배열을 정렬하겠습니다. i가 짝수이면 0을, 홀수이면 1을 x에 넣습니다. 그리고, y의 값은 i 값을 넣습니다. sort 함수로 정렬을 한 후에, 배열에 있는 내용을 출력합니다.
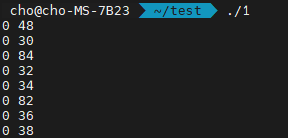
보면, 0 48이 먼저 출력되고, 0 30, 0 84, … 등이 출력되었음을 볼 수 있습니다. 이 상황을 그림으로 그려 보겠습니다.
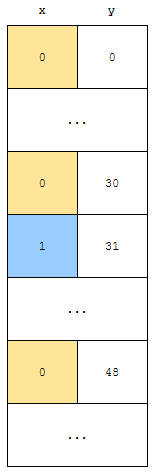
x가 0이면 노란색, 1이면 군청색으로 표시하였습니다. cmp 함수의 정의에 의하면
- x가 작은 것이 먼저 나온다.
입니다. 그런데, 결과를 보면, 아래와 같았습니다.
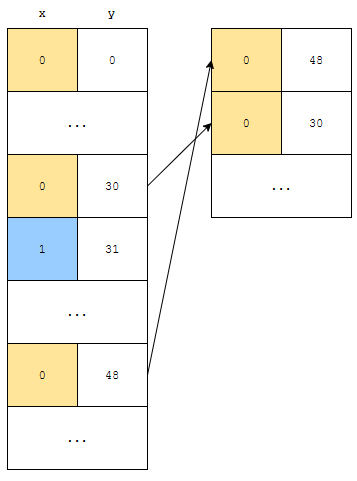
0 48이 0 30보다 먼저 나왔음을 알 수 있습니다. 이는
- x가 0인 item은 1인 item보다 먼저 나오지만
- 우선 순위가 같은 두 item의 경우 불안정 정렬의 경우 무엇이 먼저 나오는지 모르기 때문
입니다. 0 30과 0 48은 우선 순위는 같았습니다. 그리고, 기존 배열에 있었던 순서는 0 30이 0 48보다 먼저 나왔습니다. 하지만, sort 후에는 0 48이 0 30보다 먼저 나왔습니다. 즉, 우선 순위가 같은 0 30과 0 48은 기존의 순서가 유지되지 않았습니다. 이를 불안정 정렬이라고 합니다.
c++ stable sort
그러면, stable sort는 무엇일까요? 우선 순위가 같은 두 원소에 대해
- 우선 순위가 같은 두 원소에 대해
- 정렬 후에도, 기존의 순서를 그대로 유지시킵니다.
예제 1번을 수정해 보겠습니다.
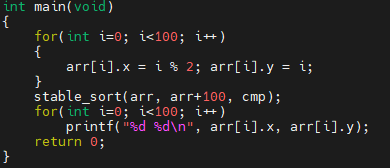
sort 대신에 stable_sort를 썼습니다. 실행 결과를 보겠습니다.
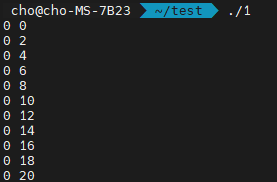
아까와는 다르게 0 0이 먼저 나오고, 그 다음에 0 2, 0 4, … 등이 나옴을 알 수 있습니다.
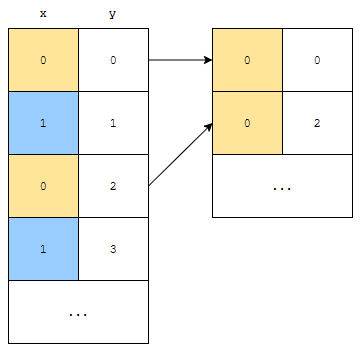
이를 도식화 시키면 위와 같습니다. 0 0과 0 2는 정렬을 할 때 우선 순위가 같았습니다.
- 정렬 전에 0 0은 0 2보다 순서상 앞에 있었습니다.
- 정렬 후에도 이 순서를 유지합니다.
c++ stable sort 함수는 우선 순위가 같다면, 정렬 전과 후에 나오는 순서가 같습니다. 이것이 sort와의 차이점이라고 할 수 있습니다.
sort만 쓰고 순서 유지하기
그러면, sort만 쓰고도 순서를 유지하는 방법이 없을까요? 간단합니다. location 이라는 필드를 하나 추가하고, compare 함수의 정의도 바꾸는 것입니다.

예제 3번 프로그램을 보면, 필드 lo가 item에 추가되었습니다. 이는 배열에 나타난 위치를 의미합니다. cmp 함수의 정의는 아래와 같이 바뀌었습니다.
- x가 다르다면, x가 작은 순으로 정렬해 주세요.
- x가 같다면, lo가 작은 순으로 정렬해 주세요.
고로, x가 같다면, 나타난 위치가 작은 순으로 정렬이 됩니다.
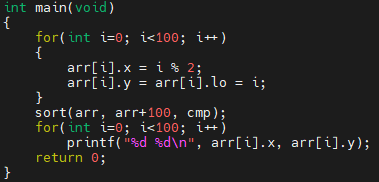
다음 arr[i].lo에 배열의 위치를 넣습니다. 실행시켜보면, 예제 2번과 동일한 결과가 나옵니다.