python counter 클래스는 key의 개수를 세는 데 특화되어 있는 함수입니다. 직접 구현해도 되지만, 3 ~ 4줄의 귀찮음은 덤입니다. 또한 추가 기능을 제공하기도 하는데요. most_common와 같이 제일 많이 나온 원소들을 구할 수도 있습니다.
이 글에서는 이런 함수들을 아는 것이 목적이 아닙니다. Counter가 어떻게 동작하는지 알아봅니다. 쓸만한 함수들은 후에 소개하도록 하겠습니다.
key값에 대응되는 value 얻기
python counter 에서 키가 없으면 어떻게 동작할까요? 예를 들어, c가 counter 객체라고 해 보겠습니다. ‘v’가 없으면 어떻게 동작할까요? 이 글에서도 설명했다시피, c[‘v’]는, __getitem__ 함수를 호출해요. 이 함수는 키 ‘v’가 없으면 __missing__을 호출해요.
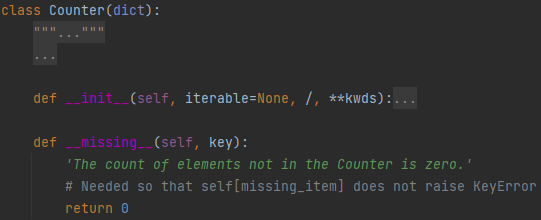
Counter의 __missing__ 함수를 보니까, 0을 돌려준다고 되어 있어요. 흐름도를 봅시다.
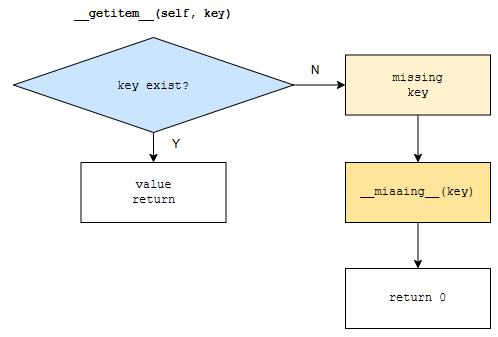
counter c 객체에 대해 c[key]를 호출하였습니다. 그러면, __getitem__이 호출될 겁니다. 만약에, key가 있으면, 그냥 value를 돌려줍니다. 그렇지 않으면, __missing__ 이 호출되어서 0을 돌려주게 됩니다. 여기까지 정리하면, 키가 없을 때 대응값 0을 돌려준다고 이해하면 되겠습니다.
생성 및 update 함수
생성과 update 함수를 보면서 어떻게 동작하는지 봅시다.
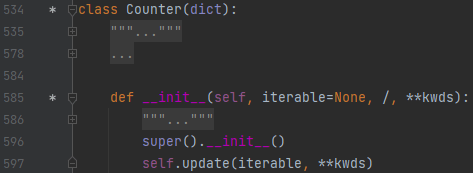
__init__ 함수에서, self.update(iterable) 이라고 되어 있습니다. 그리고 뒤에는 **kwds 라고 되어 있는데, 키워드 인자를 의미합니다. 이 함수 내부로 들어가 보겠습니다.

상당히 복잡해 보이는데요. map이나 list 같은 것으로 들어오면 iterable이 None이 아닙니다. 678번째 줄에 걸렸을 때 어떻게 동작하는지 보겠습니다.
- Map 계열인가?
- Map 계열은 아니지만 순회 가능한가?
이 두 케이스로 나누어서 보면 됩니다. 먼저 Map 계열인 경우에는 아래와 같이 들어왔을 겁니다.
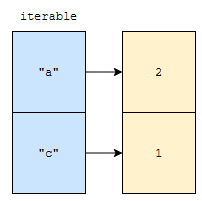
이 경우, 682번째 줄에 따라, iterable.items()를 for loop로 돌리면, elem와 count가 (“a”, 2), (“c”, 1) 순으로 뽑힐 겁니다. 그렇다면 아래와 같이 수행될 겁니다.
- self[“a”]에 2 + self_get(“a”, 0)의 값을 업데이트 하세요.
- self[“c”]에 1 + self_get(“c”, 0)의 값을 업데이트 하세요.
그런데, 이 self_get의 2번째 인자가 0이네요? 이는 키가 없는 경우 0을 돌려준다는 의미입니다.
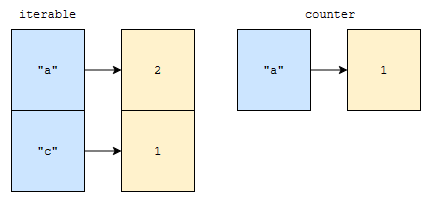
counter에 위와 같이 데이터가 있었다고 해 보겠습니다. update({“a”: 2, “c”: 1})을 수행한 후에 “a”에 대응되는 value 값은 1에 2를 더한 값인 3이 될 겁니다. “c”에 대응되는 value 값은 1에 0을 더한 값인 1이 될 겁니다.
update 함수는 빈도수를 더한다 정도로 생각하시면 됩니다. 반대로 list로 주어지는 경우는 어떻게 될까요? 이 경우에는 _count_elements를 탈 겁니다.
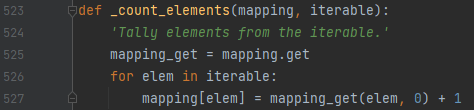
이것을 보면, 아래와 같은 일을 수행하고 있음을 알 수 있어요.
- mapping[elem]에 mapping_get(elem, 0)에 1을 더한 값을 넣어요.
- iterable에 있는 item을 모두 순회하면서
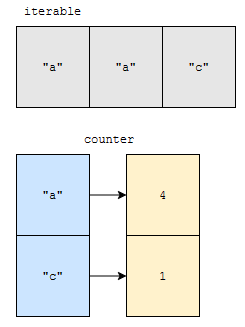
counter c가 있었습니다. 아래와 같은 상태에서 c.update([“a”, “a”, “c”])를 호출했다고 해 봅시다.
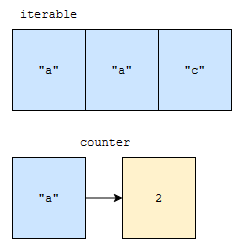
counter에는 “a”가 2개 있었습니다. update의 인자에 list가 들어갔는데요. list도 iterable 합니다. 고로, 원소를 순회하면서 counter에 빈도수를 업데이트 할 겁니다. “a”를 2개 본 후에 counter에는 아래와 같이 업데이트 됩니다.
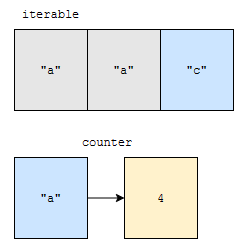
다음에 “c”를 봅니다. “c”는 없었기 때문에 get의 2번째 인자인 0이 리턴됩니다. 그리고, 1이 추가되어, counter에는 “c”가 1개 있다는 정보가 들어가게 됩니다.
이제, “a”의 빈도수를 하나 감소시키려고 해요. 어떻게 하면 좋을까요?

subtract을 이용하면 됩니다. map으로 넘겨주는 경우, 얼마만큼 뺄 지를 넘겨주면 됩니다. 그리고 list로 넘겨주면, key의 등장 횟수만큼 차감되는 것을 알 수 있습니다. pop(key)와는 다른데, pop은 map에서 key를 제거하는 것입니다. 주의해야 합니다.
한 마디로, python counter 클래스는 키 key가 몇 번 나왔다는 정보를 저장하는 collection이라고 생각하면 됩니다.
예제 몇 가지
그러면, 예제 몇 개를 보겠습니다.
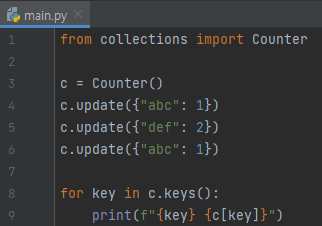
counter에 update 함수로 키를 추가하고, counter에 있는 key와 value를 출력합니다.”abc”의 빈도가 1이라는 정보를 2번 추가하고, “def”의 빈도가 2라는 정보를 1번 추가했어요. 그렇기 때문에, 결과는 아래와 같이 나옵니다.

abc가 2번 나오고, def가 2번 나왔다.
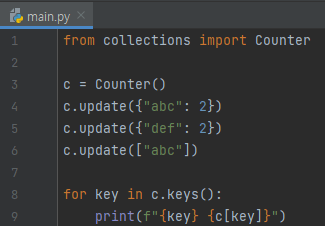
이제 예제 2번을 보겠습니다. 이번에는 6번째 줄에, update의 인자로 [“abc”]를 넘겨주었습니다. 이는 “abc”의 빈도를 하나 더 추가하는 것입니다. 4번째 줄과 5번째 줄은 “abc”와 “def”의 빈도가 각각 2번 나왔다는 것입니다. 이 정보들이 모두 합쳐지므로, 최종 결과는 아래와 같이 나옵니다.
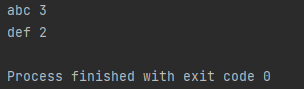
“abc”가 3번 나왔고, “def”가 2번 나왔다. 만약에, 6번째 줄의 update에 [“abc”] 대신 “abc”를 넘겨주면 어떻게 될까요? “abc”도 iterable 합니다. 어떤 원소로 이루어 졌나요?
- 문자 a
- 문자 b
- 문자 c
아래 프로그램의 경우, 문자 “a”, “b”, “c”가 각각 1번씩 나왔다는 정보가 counter에 들어갑니다.

예제 3번을 보겠습니다. 이 프로그램은 어떤 정보가 들어가나요?
- “abc”가 2번 나왔다.
- “def”가 2번 나왔다.
- “a”, “b”, “c”가 각각 1번씩 나왔다.
따라서, 합쳐진 정보는 아래와 같습니다.

“abc”의 빈도수는 3이 아닌 2입니다. 왜냐하면 6번째 줄에서, c.update(“abc”)를 호출하면, “a”, “b”, “c”가 1번씩 나왔다는 정보가 추가되었기 때문입니다.