python deque index 접근 연산은 생각보다 빠르게 수행되기 때문에, O(1) 근방인 것으로 착각하기 쉬워요. 어떻게 동작하는지 간단하게 알아보도록 하겠습니다.
python deque index 접근
먼저, 이 프로그램을 보겠습니다.
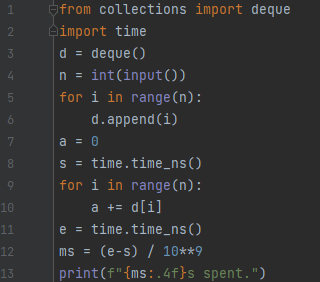
deque의 []는 배열과 같이 index에 접근하기 위한 연산자입니다. 예를 들어, deque d에서 d[3]은 3번째 요소에 접근하는 것입니다. 배열과 사용법이 크게 다를 바가 없어요. 예제 프로그램 1번에서는 길이가 n인 덱을 생성한 다음에, 0번째 원소부터 n-1번째 원소까지 접근하는 총 시간을 측정하고 있어요.

n이 10만일 때 실행 결과를 봅시다. 길이가 10만인 deque에 대해, 0번째 인덱스, 1번째 인덱스, … , 9999번째 인덱스에 접근하는 데 걸린 총 시간이 0.1초밖에 걸리지 않았어요. 상당히 빠른 것처럼 보입니다. 시간 복잡도의 경향성을 보려면, 조금 큰 데이터를 가지고 실험해 보아야 하는데요.
n이 50만일 때와 100만일 때 실험해 보도록 하겠습니다.
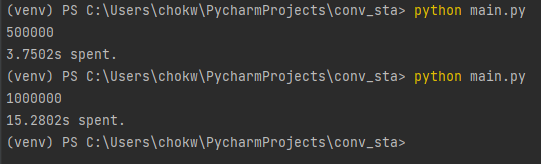
50만일 때 3.75초, 100만일 때 15.28초가 걸렸습니다. 2배 늘어날 때 4배가 증가하는 경향성을 보이고 있어요. 심지어, 데이터가 커져서 비효율적으로 동작한다는 것이 눈에 보이는 상황입니다. 결국, deque에서 index에 접근하는 연산은 덱의 크기가 n이라면 O(n)이라는 것입니다.
다른 실험을 해 보겠습니다.
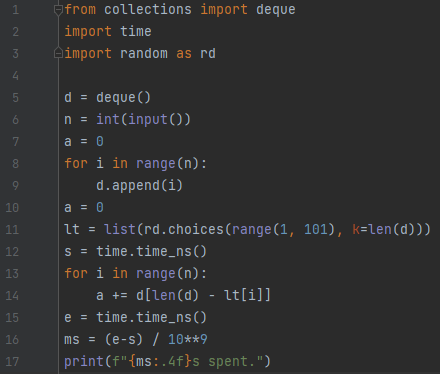
2번 프로그램을 보겠습니다. lt에, 1부터 100까지 수 중에 random 하게 하나 뽑습니다. 몇 개를 뽑는가? deque 길이만큼 뽑습니다. 이걸 어디에 쓰는가? 뒤에서 x번째 원소를 뽑기 위해 씁니다. 이 x는 맨 뒤에서 가깝다는 특징을 가지고 있어요.
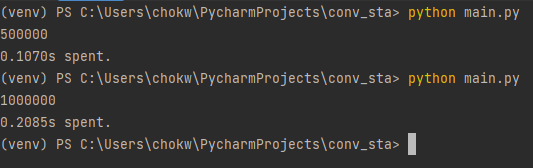
실행 결과를 볼까요? 아까와는 다르게, n이 50만일 때도, 100만일 때에도 꽤 효율적으로 동작함을 볼 수 있어요. 이는, 앞이나 끝과 매우 가까우면 O(1), 혹은 그에 준하는 효율로 동작함을 의미합니다. 여기까지 정리해 봅시다.
- python deque의 index 연산은
- 시작 지점에서 가까운 곳을 가져오는 것도 빠릅니다.
- 끝 지점에서 가까운 곳을 가져오는 것도 빠릅니다.
- 중간 지점이 비효율적인데, 상수가 많이 낮습니다.
deque는 어떤 구조로 이루어져 있는가?
그러면, python의 deque는 어떤 구조로 이루어져 있을까요? 이 링크 를 보면 간단하게 알 수 있습니다. 이를 그림으로 설명해 보겠습니다.
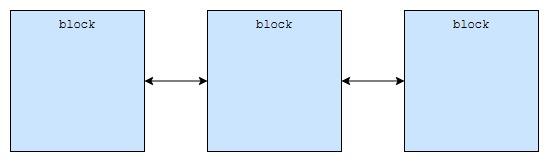
deque는 block 들로 이루어져 있습니다. 각 block 들은 linked list로 연결되어 있는데요. 앞, 뒤로 이동 가능해야 하기 때문에 double linked list로 구현이 되어 있습니다.
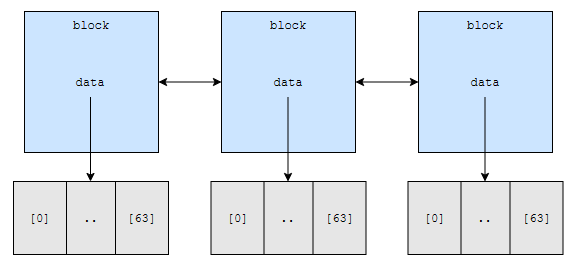
이 block 안에는 data가 있는데요. data 안에 64개의 원소들을 저장하고 있습니다. 따라서, 시작이나 끝에서 n만큼의 거리가 떨어져 있어도, O(n/64) 만큼 링크를 타고 이동한 다음에, 많아봤자 64회만큼 탐색을 더 하면 됩니다.
이 구조에서는, index에 접근하는 데 시간은 오래 걸립니다. 하지만, 왼쪽이나 오른쪽으로 확장하는 경우 head와 tail만 알고 있으면 상당히 빠르게 추가할 수 있습니다. 64 x 128 개의 원소가 요래 있다고 했을 때, 64번째 원소와 64 x 127 – 1번째 원소에 어떻게 접근하는지 로직을 그려 볼게요.
deque의 index의 동작 방식
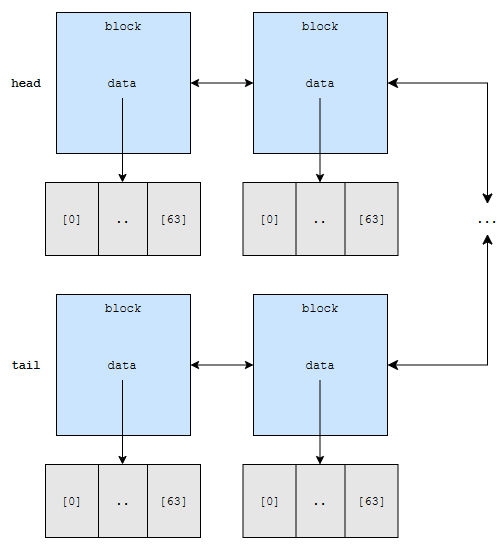
아래와 같이 저장되어 있다고 해 볼게요. 당연하게도 원소가 추가되고 제거됨에 따라서, block에 있는 데이터 수는 바뀔 수 있어요. 특히 시작과 끝 block 에서는요. 여기에서는 단순하게 64개의 block이 모두 채워져 있다고 해 보겠습니다.
64번째 원소를 찾으려고 해요. 그러면, head 쪽이 더 가깝기 때문에, head에서부터 찾기 시작합니다. 그런데, head에는 0번째 원소부터 63번째 원소만 있어요. 건너 뛰겠지요?
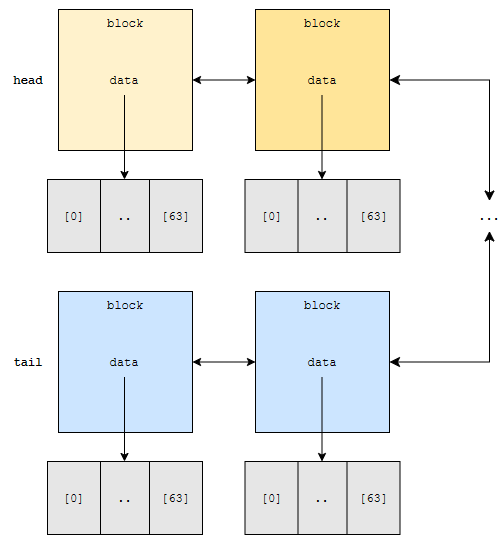
고로, rightlink를 타고, right block으로 가요. 여기에는 64번째 원소부터 127번째 원소까지 있어요. 64번째 원소는 data의 몇 번째에 있어요?
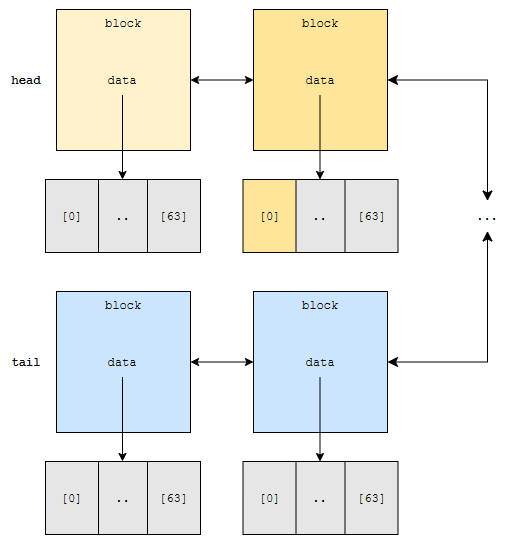
0번째에 있어요. 가져오면 됩니다. 다음, 64 x 127 – 1번째 원소를 찾고 싶어요. 이건 또 어떻게 할까요? 총 64 x 128개의 원소가 있으므로, head가 아니라 tail에 더 가깝습니다.
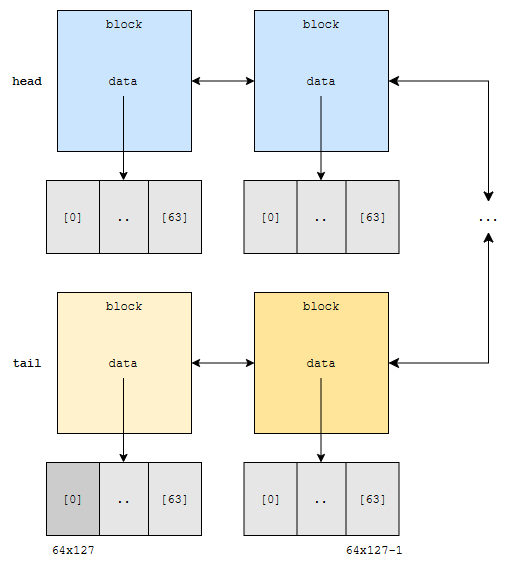
고로 tail부터 찾을 텐데, 맨 마지막 block은 64×127번째 원소부터 64×128 – 1번째 원소까지를 저장하고 있어요. 이 범위에, 64×127 – 1이 없어요. 따라서, leftlink를 타고, left block으로 갑니다.
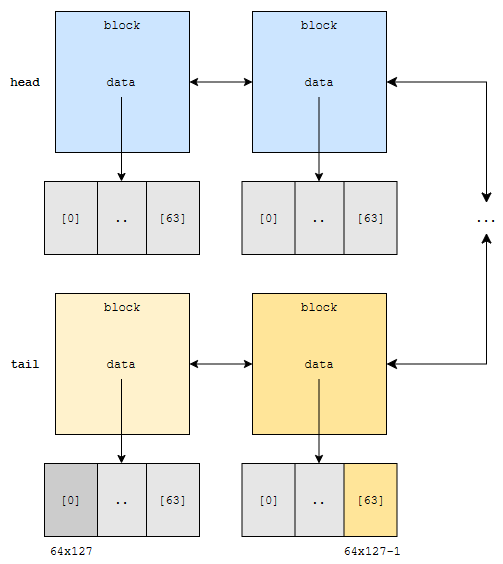
left block을 보니까, 64×126부터, 64×127 – 1번째 원소까지 data에 저장하고 있어요. 고로, data의 맨 끝 부분에서 가져오면 됩니다. 결국 block 단위로 뛰는 게 핵심인 셈입니다.