ps에서 좌표압축을 하기 위해, c++ unique 함수를 많이 쓰게 됩니다. 이 함수가 어떻게 동작하는지, 그리고 어떻게 쓰는지 이 글에서 간단하게 알아보도록 하겠습니다.
c++ unique 함수 사용하기
사용법은 아래와 같습니다.
- first
- unique 함수를 적용할 시작 iterator
- last
- unique 함수를 적용할 끝 iterator의 다음 위치
- 리턴값
- 제거된 최초의 위치 (의미없는 데이터의 최초 위치)
즉, [first, last) 구간에 unique 함수를 적용한다고 볼 수 있어요. 이 함수를 적용하면, 연속적으로 같은 값에 대해 제거해 주는데요. 어떻게 동작하는지 간단하게 보겠습니다. 예를 들어, 아래와 같은 데이터가 있다고 해 보겠습니다.
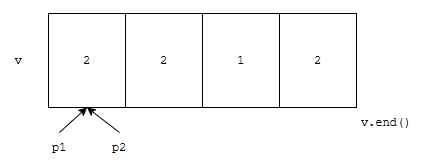
처음에는, p1과 p2가 같은 위치를 가리키고 있을 겁니다. 여기서, 우리는 p1이 있는 위치에 2를 넣었습니다.
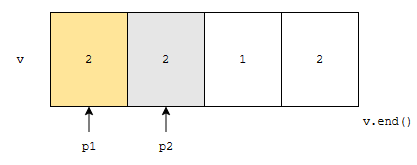
다음, p2만 한 칸 오른쪽으로 이동해 봅니다. 그러면, p1이 가리키는 값과 p2가 가리키는 값이 같아요. 중복이 되기 때문에, 그냥, p2가 가리키는 값을 p1이 가리키는 곳에 넣고, p2만 오른쪽으로 한 칸 이동시킵니다.
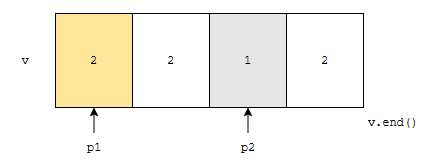
다음에, p1이 가리키는 값과, p2가 가리키는 값이 다릅니다. 2와 3은 다르기 때문에, p1을 한 칸 오른쪽으로 이동합니다.
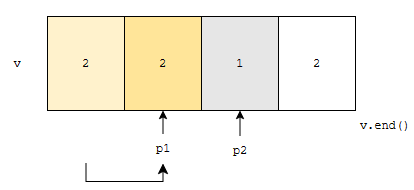
이제, p2가 가리키는 곳에 있는 값을, p1이 가리키는 곳에 넣습니다.
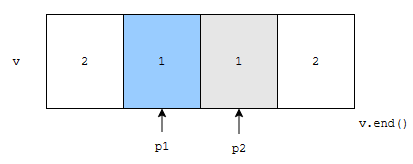
그러면, 위와 같은 상황이 그려집니다. 다음에, p2를 오른쪽으로 한 칸 이동시킵니다.
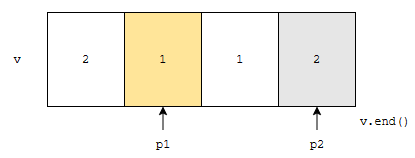
p1이 가리키는 값과 p2가 가리키는 값이 다릅니다. 1과 2는 다릅니다. 따라서, p1을 1칸 오른쪽으로 이동한 다음에, p2가 가리키는 값을 p1이 가리키는 곳에 넣습니다.
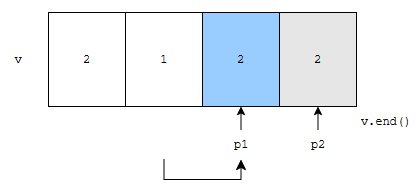
그 다음에, p2를 1칸 이동시킵시다.
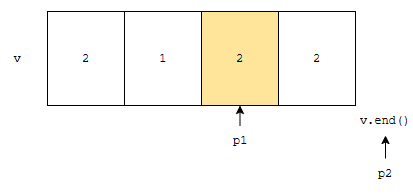
그런데, p2는 end()를 가리키고 있지요? 따라서, 리턴값은 p1의 다음 위치가 됩니다.
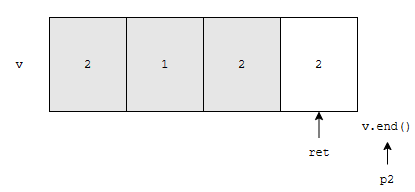
이 ret는 의미 없는 데이터의 최초의 위치라고 할 수 있어요. 여기까지 c++ unique 함수가 어떤 식으로 동작하는지 이해가 되시리라 믿습니다.
입력에 따른 결과 분석해 보기
이제, c++ unique 함수의 결과들을 분석해 봅시다.
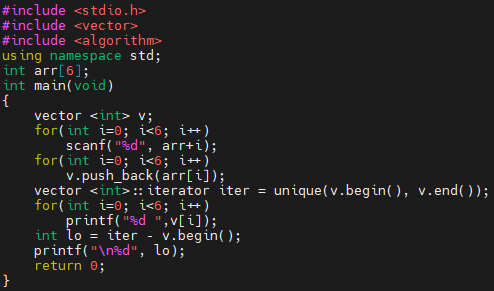
먼저, 예제 프로그램 1번입니다. 간단하게 6개의 수를 입력받아, 벡터 v에 넣고 unique 함수를 호출합니다. 그리고 벡터 v에 들어있는 내용과, unique 함수의 리턴값을 이용합니다. 그런데, int lo 부분이 하나 있어요. iter에서 v.begin()을 빼는 부분이요. iterator끼리 빼면, 예를 들어 iter1 – iter2를 하면, iter2에 대해, iter1이 얼마나 멀리 떨어져 있는지를 돌려줘요. 예를 들어 iter1이 iter2보다 4칸 오른쪽에 있으면 4가, 왼쪽에 있으면 -4가 리턴될 겁니다.
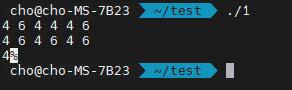
입력 1번은 4 6 4 4 4 6을 넣었습니다. 그에 따른 결과가 1번째 줄에는 4 6 4 6 4 6이 나왔고, 2번째 줄에 4가 출력 되었습니다. 어떻게 된 것인가?
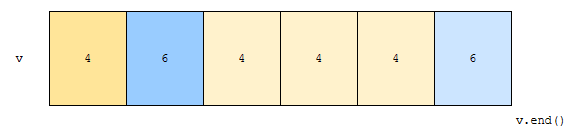
연속적으로 같은 것끼리 묶어봅시다. 그러면 4 하나 묶이고, 6 하나 묶이고, 다시 4 3개가 묶이고, 그 다음에 6이 묶입니다. 따라서, 4 6 4 6 이렇게 오게 됩니다.

나머지 2개는 어떻게 될까요? 사실상 의미 없는 데이터입니다. 따라서, uniq의 결과는 4번째 원소인 4를 가리키는 iterator가 나오게 됩니다. 여기서 v.begin()을 빼니, 4가 나오는 셈이지요. 이후에 좌표 압축을 하기 위해, ret부터 v.end()까지 제거해 주면 되겠지요.
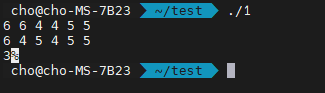
그러면 이 입력은 어떨까요?
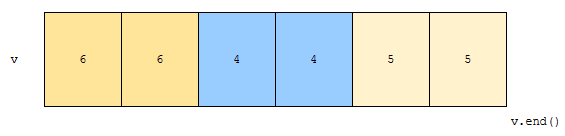
이 경우, 앞의 2개의 6이 한 묶음으로, 다음 4 2개가 또 한 묶음으로, 다음 2개의 5가 한 묶음으로, 이렇게 3개의 묶음으로 묶어지게 됩니다.
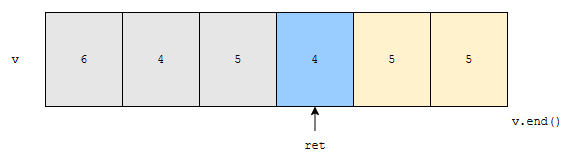
따라서, 이 경우, 벡터의 경우 6 4 5 4 5 5가 되고, ret는 3번째 원소인 4를 가리키게 됩니다.
왜 정렬하고 unique를 쓰는가?
우리는 보통 정렬한 후에 unique를 씁니다. ps에서도 마찬가지입니다. 왜 그럴까요? 같은 값이 인접하게 모이게 하는 방법 중 하나가 sort이기 때문입니다. 같은 값이면 같은 덩어리 안에 묶인다는 것이 핵심입니다.
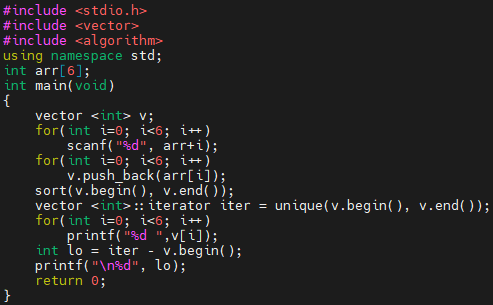
예제 2번 프로그램을 봅시다. unique를 호출하기 전에 sort를 불렀습니다.

결과를 봅시다. 6 4 6 4 6 4 이렇게 입력을 주어도, 정렬이 되므로 4 4 4 6 6 6이 되고, 4와 6 2개의 덩어리로만 묶이게 됩니다. 최종적으로 iter는 2번째 원소인 4를 가리키게 됩니다. 이 특성을 이용해서, erase로 후처리 해 주면 중복 제거를 할 수 있습니다.