이 글에서는 sql distinct에 대해 다루게 됩니다. 그리고, 이전 글에서 설명했던 group by와 어떻게 다른지도 알아봅니다. 초급 시리즈에 원래 없었던 글이지만, 높은 빈도로 많이 써서 추가하게 되었습니다. 혹여나, 다른 글을 보고 싶으시다면, 아래 목록을 참고해도 좋겠습니다.
- from 절과 카티션 곱에 대해 이해해 봅시다.
- order by 절로 정렬해 봅시다.
- group by 절에 대해 알아봅시다.
- having 절과 where 절의 차이를 알아봅시다.
- select 절과 as 절에 대해 알아봅시다.
- 결과에서 중복을 제거하는 방법을 알아봅시다. [현재글]
sql distinct 문
먼저, sql distinct 문은 중복을 제거하기 위해 쓰입니다. 보통, 아래와 같이 쓰이게 됩니다.
distinct col1, …
col1, … 이 중복되면 결과에서 제거합니다.
group by와 비슷해 보이지 않느냐고 물어볼 수 있습니다. 밑에서도 후술하겠지만, 용례가 다릅니다.
- 결과 컬럼의 중복 제거를 위해 쓰는 distinct
- 특정한 기준으로 그룹화 하기 위해서 group by
뉘앙스도 같지 않습니다. 사용에 조심해야 합니다. 몇 가지 쿼리 예제를 보겠습니다.
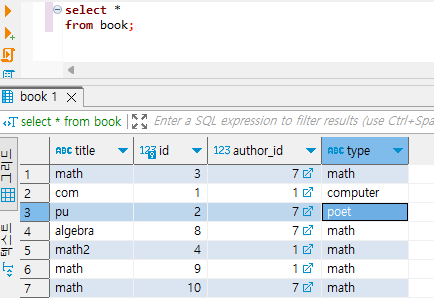
book 테이블에는 책 데이터들이 모두 있습니다. 문제 1번. 모든 책의 title을 뽑고 싶어요. 그런데, title이 같은 것은 중복되어 나오면 안 됩니다. 그러면 book에서 결과를 선택하였는데, 중복을 제거해야 하는 것이 title 임을 알 수 있어요.
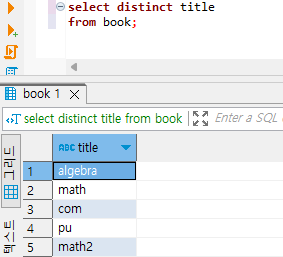
따라서, book으로부터 결과를 얻어오는데, title만 제거하면 되기 때문에, distinct 절 뒤에 title을 써 주면 됩니다. 여기까지 정리해 볼게요.
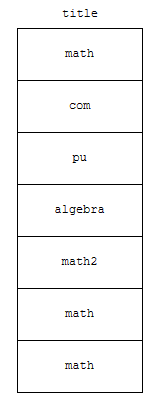
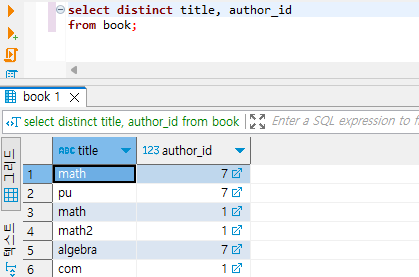
title의 중복을 제거하지 않았다면, 위와 같이 나올 겁니다.
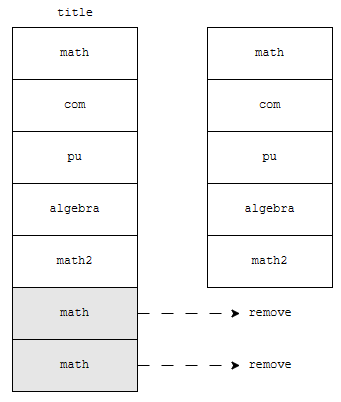
distinct title을 했기 때문에, 6번째 math와 7번째 math는 제거됩니다. title이 같기 때문에, 결과에 표시되지 않은 것입니다. 그런데, 다른 작가가 쓴 같은 이름의 책은 어떤가요? 다른 작가이지만, 같은 이름을 쓴 책이 여러 개 나올 수 있어요.
그래서, 저는 책 이름이 같으면서, 같은 작가가 쓴 책을 같은 책이라고 하기로 했어요. 즉
- title이 같으면서
- author_id가 같은
책을 중복 처리하기로 했어요. 어떻게 해야 할까요?
distinct 뒤에 title과 author_id를 넣어주면 됩니다. 위의 경우, title과 author_id가 같다면 중복으로 처리해 버립니다.
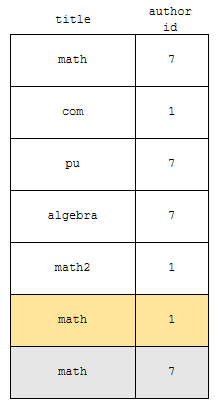
그림을 봅시다. 6번째 행은, 1번째 행과 title이 같습니다. 하지만 author_id가 다릅니다. 1번째 행의 작가 id는 7이지만, 6번째 행은 1이기 때문입니다. 따라서, 노란색으로 표시된 행은 결과에서 제외되지 않습니다. 하지만, 회색으로 표시한 것은 어떤가요? title이 math이고, author_id가 7인 것은 이미 있어요.
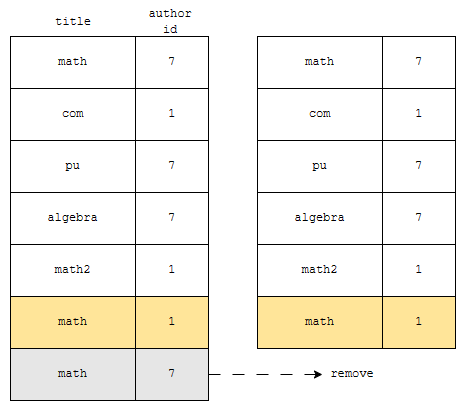
따라서, 6개의 행만 나오게 됩니다. 정리하면 distinct 뒤에 컬럼들을 적어주면, 해당 컬럼들이 모두 같은 것은 하나만 나오게 합니다.
group by 와의 차이점
그러면 group by 와 어떤 점이 다를까요? distinct가 단순히 결과에서 중복을 제거하는 것이라면, group by는 특정한 기준으로 그룹화를 시키는 것입니다. 예를 들어, 책 type별로 group by를 시켰다고 해 봅시다.
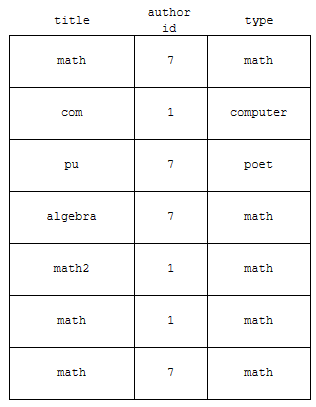
기존 데이터가 위와 같이 있었다고 해 보겠습니다. type을 기준으로 group화를 시키면 아래와 같이 됩니다.
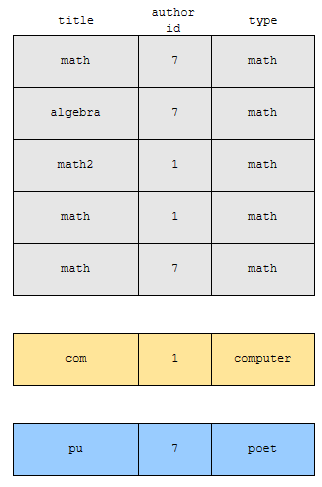
특정한 기준으로 묶었다면, 집계 함수를 쓸 수 있습니다. 예를 들어, type 별로 count 하면 어떻게 될까요?
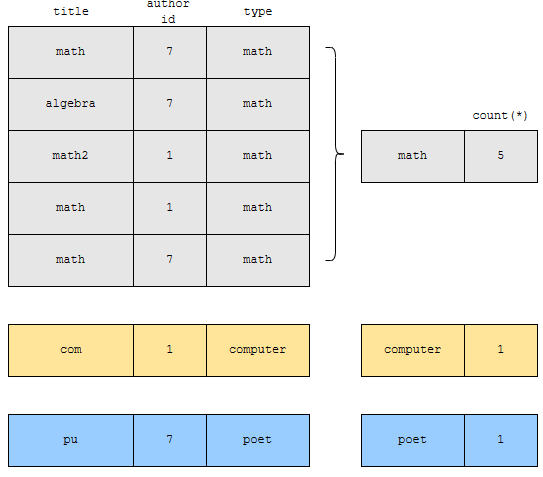
즉, 집계를 하기 위해 그룹별로 묶는 전처리를 하는 것이 group by입니다. 이 글에서도 헷갈릴까봐 꽤 자세하게 설명했으니, 보셔도 좋겠습니다.